I had access to my first Macintosh computer around 1987. My father brought it home and I spent hours on it playing games and occasionally writing reports for school. The Macintosh Plus computer had one floppy drive and no hard drive. I remember playing the game Orbiter which had two floppy disks and right in the middle of game play it would pause and ask me to insert disk 2, then quickly ask for disk 1 again. The struggle was real. I spent years using many different Macintosh computers and now own more than I wish to admit. I’m preserving them!
The wild world of digital preservation has been a little lacking on the Macintosh side of things as I have come to realize. There still not a great way to manage Resource Forks in many preservation systems and the identification tools are mainly focused on the data bytetreams and not any system specific attributes Macintosh used often.
The PRONOM registry has either referenced early Macintosh specific formats or missed them entirely so I have been slowly working on a few to close that gap.
Interestingly enough, many Microsoft programs initially made their GUI debuts on the early Macintosh before making their way to Windows. Excel is one I am working on, as Version 1 is not identifiable in PRONOM, it was Macintosh only at the time.
Another is PowerPoint, I recently submitted two new signatures to PRONOM.
fmt/1747: Microsoft PowerPoint Presentation v2.x. Full entry added. fmt/1748: Microsoft PowerPoint Presentation v3.x. Full entry added. fmt/1866: Microsoft Powerpoint for Macintosh v.2. Full entry added. fmt/1867: Microsoft Powerpoint for Macintosh v.3. Full entry added.
PowerPoint was initially released in 1987 on the Macintosh platform. It was developed by a company called ForeThought. Version 1.0 on the Macintosh was under this name, until it was bought by Microsoft only three months after being released. The history of PowerPoint can be discovered at Robert Gaskins, one of the original developers, website and book he wrote. The available information provided by Microsoft is only for the OLE format, covering versions 4.0 until 2003.
So, lets take a look at the Powerpoint original file format, before OLE.

Type/Creator RF DF Date Filename f SLDS/PPNT 0 932 Oct 10 19:10 PowerPoint-v1
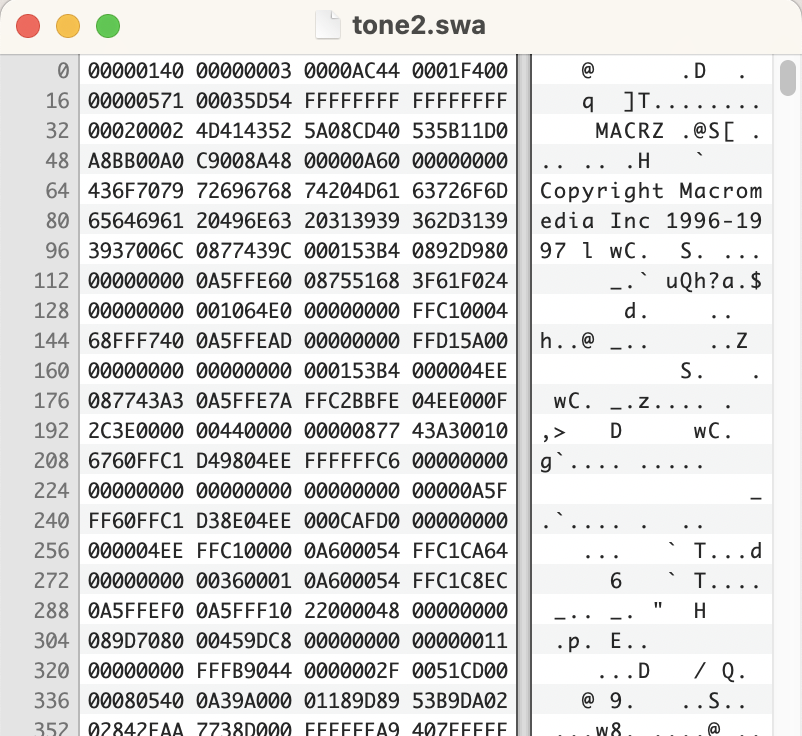
Luckily the early PowerPoint files did not have a Resource Fork. The Data Fork, if you haven’t noticed, has an interesting set of hex values at the beginning of the file. 0BADDEED is the first 4 bytes. If we look at a PowerPoint version 2 file from Windows.

The file format is the same, but because of the weird world of endianness, the first few bytes are in reverse order, EDDEAD0B.
Obviously we need to discuss this magic number and the meaning behind “Bad Deed”. This question was asked previously by the digital preservation community. I have a previous blog post about the use of words for the magic number CAFEBEEF as it was used with with JAVA class files and Express Publisher in the 1990’s. BADDEED looks like another clever use of the hex values that formed words. But was there a story behind the words? Joe Carrano asked if this string might be hexspeak. I wanted to know more so I asked some one who might know.
Robert Gaskins was kind enough to chat with me for a bit about the early days of PowerPoint.
I had a theory on the possible meaning behind BADDEED, so I asked him what the feeling was like between Apple and Microsoft at the time. I had heard for years that PowerPoint was originally created for the Macintosh, but Robert informed me:
In fact, PowerPoint was designed first for Microsoft Windows,
and its first spec shows that: “All the screen shots, menus, and
dialogs were set up to look like Microsoft Windows, not like
Macintosh.” (Gaskins, Sweating Bullets, p. 92) You can see that
spec here.
A year later, we concluded that we would be forced to ship
on Mac first, although we still thought that Windows was the
big opportunity and thought that Mac was risky. “We just didn’t think
we could successfully ship a product for Windows, yet, though we planned
to later. (Gaskins, Sweating Bullets, p. 105) The considerations are
summarized in my June 1986 product marketing document.
Of course, we turned out to have been right all along. PowerPoint on
Mac was much loved, but sales remained poor because Mac sales were
so poor. It was only after we shipped on Windows that PowerPoint gained
the dominant market share which has characterized it ever since, and
Windows PPT outsold Mac PPT very quickly. (Gaskins, Sweating Bullets, p. 403)
So my original thought was that there was some bad feelings around this Apple, Microsoft battle which has been the sentiment for quite some time. So when I asked if any of that influenced the use of BADDEED, I was told:
So, far from being disgruntled by expanding PowerPoint to Windows,
that had been our goal all along, and its achievement was the most
important success we had.
I judge that you are fully aware of all that, and that
your question is more, “was there any bad deed signified
by the Mac hex value chosen?” No, it was just the poverty
of choice when you only have six letters.
So there you have it. The use of the hex values 0x0BADDEED, was simply chosen from a limited set of values when looking at words hexadecimal could spell. I guess I should never let the truth get in the way of a good story.
I continued to have a wonderful conversation with Robert and also asked him for some details on the rest of the PowerPoint file format. I was hoping there might be some documentation out there explaining the early format before Microsoft took over. Robert said:
I don’t know of any such documentation apart from the official
Microsoft support files available online. I don’t have any such
information. I know that Dennis Austin deposited some of our
working files at the Computer History Museum (not online):
and it’s likely that some information is there–if nothing
else, it claims to contain a source code listing for PPT 1.0
which would contain the code to read the file format.
So there might be some information in at the Computer History Museum worth looking into.
As far as I could tell from the available online information, there is a few differences between Version 1.0 and Version 2.0, the biggest being the fact that 1.0 did not have an option to print in color, amount a few other minor things. Here is a screenshot of a page from the Microsoft PowerPoint 2.0 documentation on archive.org.

I suppose with the signature additions of the Macintosh and Windows versions 2.0 and 3.0 of the PowerPoint file format in PRONOM, that should cover most needs. Currently my PowerPoint 1.0 files identify at 2.0 files, so I may need to have them adjust the PUID to include both versions 1.0 and 2.0 as they are so similar. If I am able to find a difference or get my hands on the original source code I may find a better solution.