There was a lot of CAD programs in the 1980’s through the 1990’s. Some titles might be TurboCAD, DesignCAD, Generic CADD, KeyCAD, SwiftCAD, CADKEY, VersaCAD, MiniCAD, EasyCAD, and of course AutoCAD. Also, many file formats. Some had chosen the common DXF exchange format, but most chose their own way to do things.
AutoCAD is software made by AutoDesk, but is one of many software tools made by them. AutoCAD has its own native file format, DWG, as is well documented, but there was a little brother to AutoCAD marketed for a few years and it also had its own format(s).
AutoSketch was a less powerful version of AutoCAD and only supported 2D models, but still found a good following of users. Unlike its big brother, the AutoSketch native format(s) don’t have much documentation and are not supported in any AutoDesk product today. The PRONOM entry for the SKF (fmt/306) is missing a signature, it is an outline entry only. In addition, SKF, AutoSketch had an earlier format that needs to be documented and a signature created. Let’s take a look.
The first version of AutoSketch came out in 1986 for DOS and files stored in RAM which could be written out as a SKD file. Looking at a saved file, we see a very easy to identify file.
% hexdump -C TEMPLATE.SKD | head
00000000 41 75 74 6f 53 6b 65 74 63 68 20 64 72 61 77 69 |AutoSketch drawi|
00000010 6e 67 20 64 61 74 61 62 61 73 65 0d 0a 1a 00 00 |ng database.....|
00000020 49 03 00 44 00 00 00 01 00 00 00 00 00 00 00 00 |I..D............|
00000030 00 00 00 00 00 40 41 00 00 10 41 00 00 00 00 00 |.....@A...A.....|
00000040 00 00 00 00 00 40 41 00 00 10 41 00 00 00 3f 01 |.....@A...A...?.|
00000050 00 09 00 00 00 00 00 00 00 00 00 00 00 00 00 33 |...............3|
00000060 33 33 33 33 33 d3 3f 00 00 00 00 00 00 f0 3f 00 |33333??......??.|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000080 00 80 3f 00 00 80 3f 0a 00 08 00 00 00 00 00 ff |..?...?........?|
00000090 ff 00 00 00 00 00 00 00 00 00 00 00 00 00 00 25 |?..............%|
Most formats don’t make it this easy. Having the ASCII string “AutoSketch drawing database” makes identification very easy. Lets see if this pattern stays true with the next version, version 2.0 for DOS.
% hexdump -C ENGINE.SKD | head
00000000 41 75 74 6f 53 6b 65 74 63 68 20 64 72 61 77 69 |AutoSketch drawi|
00000010 6e 67 20 64 61 74 61 62 61 73 65 0d 0a 1a 00 fd |ng database....?|
00000020 49 06 00 12 04 00 00 01 00 00 00 64 20 88 40 f7 |I..........d .@?|
00000030 eb 38 c2 88 fe 1b 44 25 83 dd 43 00 00 00 00 00 |?8?.?.D%.?C.....|
00000040 00 00 00 00 80 1d 44 00 80 d9 43 00 00 00 41 01 |......D..?C...A.|
00000050 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000060 00 00 00 00 00 14 40 00 00 00 00 00 00 f0 3f 00 |......@......??.|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000080 00 40 41 00 00 40 41 0a 00 08 00 00 00 00 00 1f |.@A..@A.........|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 1d |................|
AutoDesk also released version 3.0 of AutoSketch in 1990.
Version 3.0 of AutoSketch produced files which appear very similar, but needs a closer look.
% hexdump -C ASSY.SKD | head
00000000 41 75 74 6f 53 6b 65 74 63 68 20 64 72 61 77 69 |AutoSketch drawi|
00000010 6e 67 20 64 61 74 61 62 61 73 65 0d 0a 1a 00 8b |ng database.....|
00000020 49 09 00 db 00 00 00 01 00 00 00 00 00 00 00 00 |I..?............|
00000030 00 00 00 b7 cc a4 41 79 99 79 41 00 00 00 00 00 |...?̤Ay.yA.....|
00000040 00 00 00 00 00 04 42 00 00 90 41 00 00 00 3f 01 |......B...A...?.|
00000050 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 9a |................|
00000060 99 99 99 99 99 c9 3f 00 00 00 00 00 00 f0 3f 00 |.....??......??.|
00000070 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 00 |................|
00000080 00 80 3f 00 00 80 3f 0a 00 08 00 00 00 00 00 ff |..?...?........?|
00000090 00 00 00 00 00 00 00 00 00 33 33 33 33 33 f3 1e |.........33333?.|
*
000001b0 00 00 00 00 00 f0 3f 01 00 01 00 00 00 00 00 00 |.....??.........|
000001c0 00 00 00 00 00 00 00 74 78 74 00 f5 eb 0e 05 08 |.......txt.??...|
000001d0 04 15 01 08 00 eb 02 62 c0 76 32 00 fe fe fe fe |.....?.b?v2.????|
000001e0 fe fe fe fe fe fe fe fe fe 55 55 55 55 55 55 55 |?????????UUUUUUU|
000001f0 55 57 77 55 55 55 55 55 55 55 55 55 55 55 55 55 |UWwUUUUUUUUUUUUU|
00000200 55 55 55 55 55 55 35 55 53 33 55 00 00 00 00 00 |UUUUUU5US3U.....|
00000210 00 50 00 00 00 07 77 77 77 77 77 77 77 77 77 00 |.P....wwwwwwwww.|
Turns out AutoDesk made a change to the SKD format and you can see the version number at 473rd byte (0x1D9). This version of SKD is required for later versions of AutoSketch to open and use the format. A special version of AutoSketch, 2.1fc, was released with limited features to allow users to open earlier versions of the SKD format and convert them to the second version of the format. The readme file for the 2.1fc version has this statement:
This limited release of AutoSketch has been provided for file conversion purposes only. All functionality other than opening and saving files has been removed from this release.
Please follow the steps below to perform a drawing file conversion for files created in AutoSketch Release 2.0 for Windows, or earlier. Once drawing files have been converted, you will be able to open them in AutoSketch Release 5.0 and later.
AutoDesk released the first version of AutoSketch for Windows in 1992. This first version for Windows used the new SKD format as well. Even though it was version 1.0 for Windows, the new version of the format is known as the v2.x format.
% hexdump -C AS1-S01.SKD
00000000 41 75 74 6f 53 6b 65 74 63 68 20 64 72 61 77 69 |AutoSketch drawi|
00000010 6e 67 20 64 61 74 61 62 61 73 65 0d 0a 1a 00 00 |ng database.....|
00000020 49 0b 00 00 00 00 00 01 00 00 00 00 00 00 00 00 |I...............|
00000030 00 00 00 00 00 40 41 00 00 10 41 00 00 00 00 00 |.....@A...A.....|
00000040 00 00 00 00 00 40 41 00 00 10 41 00 00 80 3f 01 |.....@A...A...?.|
00000050 00 07 00 00 00 00 00 00 00 00 00 00 00 00 00 33 |...............3|
00000060 33 33 33 33 33 d3 3f 00 00 00 00 00 00 f0 3f 00 |33333??......??.|
00000070 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 00 |................|
00000080 00 80 3f 00 00 80 3f 0a 00 08 00 00 00 00 00 ff |..?...?........?|
00000090 ff 00 00 00 00 00 00 00 00 9a 99 99 99 99 99 1f |?...............|
000000a0 40 cd cc cc cc cc cc 23 40 00 00 01 00 00 00 00 |@??????#@.......|
000000b0 00 00 00 00 00 f0 3f 00 00 00 00 00 00 f0 3f 00 |.....??......??.|
000000c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000001d0 00 00 00 00 00 00 00 e8 9a 76 32 00 00 00 00 00 |.......?.v2.....|
000001e0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
This is the format used through version 2.1 for Windows which was released in 1996. It was after this version AutoDesk made a major change to the software. In version 5, skipping 3 and 4, an entirely new drawing engine was used, changing the software and the file format. This new format is actually the format used by the software the new drawing engine came from, DrafixCAD. AutoDesk purchased the software company Softdesk Drafix and used the DrafixCAD software, originally developed by Foresight Resources Corp., for this new version of AutoSketch.
Let’s compare a couple of DrafixCAD files to an AutoSketch 5 and 6 file.
% hexdump -C DEMOPLAN.CAD | head
00000000 0a 75 00 00 00 0b 02 38 30 13 05 46 4c 4f 41 54 |.u.....80..FLOAT|
00000010 14 05 53 48 4f 52 54 0c 04 30 2e 38 30 0d 08 4f |..SHORT..0.80..O|
00000020 63 74 20 31 39 38 39 0e 12 44 72 61 66 69 78 20 |ct 1989..Drafix |
00000030 57 69 6e 64 6f 77 73 20 43 41 44 0f 06 49 42 4d |Windows CAD..IBM|
00000040 20 50 43 10 07 44 4f 53 20 33 2e 30 11 06 4d 53 | PC..DOS 3.0..MS|
00000050 20 32 2e 31 12 1e 31 39 38 39 20 46 6f 72 65 73 | 2.1..1989 Fores|
00000060 69 67 68 74 20 52 65 73 6f 75 72 63 65 73 20 43 |ight Resources C|
00000070 6f 72 70 2e 00 28 43 03 00 00 29 b6 01 00 00 01 |orp..(C...)?....|
00000080 07 00 02 01 00 04 01 00 05 01 00 06 01 00 07 00 |................|
00000090 00 80 3f 08 00 00 09 0d 00 0a 01 00 0c 04 00 11 |..?.............|
% hexdump -C DEMOPLAN.CAD | head
00000000 0a 7d 00 00 00 0b 03 32 30 30 13 06 44 4f 55 42 |.}.....200..DOUB|
00000010 4c 45 14 05 53 48 4f 52 54 0c 03 32 2e 30 0d 0f |LE..SHORT..2.0..|
00000020 4a 61 6e 75 61 72 79 20 37 2c 20 31 39 39 32 0e |January 7, 1992.|
00000030 12 44 72 61 66 69 78 20 57 69 6e 64 6f 77 73 20 |.Drafix Windows |
00000040 43 41 44 0f 06 49 42 4d 20 50 43 10 07 44 4f 53 |CAD..IBM PC..DOS|
00000050 20 33 2e 30 11 06 4d 53 20 32 2e 31 12 1e 31 39 | 3.0..MS 2.1..19|
00000060 38 39 20 46 6f 72 65 73 69 67 68 74 20 52 65 73 |89 Foresight Res|
00000070 6f 75 72 63 65 73 20 43 6f 72 70 2e 00 28 28 04 |ources Corp..((.|
00000080 00 00 29 80 02 00 00 04 01 00 05 01 00 07 00 00 |..).............|
00000090 00 00 00 00 00 40 08 01 00 0a 01 00 0c 04 00 11 |.....@..........|
% hexdump -C ASv5-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 30 31 01 00 00 00 38 00 |.......401....8.|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
% hexdump -C ASv6-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 30 32 03 36 2e 30 01 20 |.......402.6.0. |
00000010 0f 4f 63 74 6f 62 65 72 20 32 2c 20 31 39 39 38 |.October 2, 1998|
00000020 01 00 00 00 38 00 00 00 00 00 00 00 00 00 00 00 |....8...........|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
You can see the similar pattern in the first 8 bytes. Just the 2nd and 7th byte being different. The 8th byte is consistent with all SKF files, and the 9th and 10th bytes turn out to be in sequence depending on the version.
Looking at the next few versions of AutoSketch we see:
% hexdump -C AS7-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 31 32 03 37 2e 30 08 42 |.......412.7.0.B|
00000010 75 69 6c 64 20 35 34 10 4f 63 74 6f 62 65 72 20 |uild 54.October |
00000020 31 35 2c 20 31 39 39 39 01 00 00 00 38 00 00 00 |15, 1999....8...|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
% hexdump -C AutoSketch8-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 31 32 03 39 2e 30 08 42 |.......412.9.0.B|
00000010 75 69 6c 64 20 38 38 0a 30 37 2f 30 38 2f 32 30 |uild 88.07/08/20|
00000020 30 34 01 00 00 00 38 00 00 00 00 00 00 00 00 00 |04....8.........|
00000030 00 40 00 00 00 00 00 00 1f 40 00 00 00 00 00 00 |.@.......@......|
00000040 00 00 00 00 00 00 00 00 00 40 00 00 00 00 00 00 |.........@......|
00000050 20 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | @..............|
00000060 00 00 02 00 00 00 76 5e 00 00 42 4d 76 5e 00 00 |......v^..BMv^..|
00000070 00 00 00 00 76 00 00 00 28 00 00 00 00 01 00 00 |....v...(.......|
00000080 bc 00 00 00 01 00 04 00 00 00 00 00 00 5e 00 00 |?............^..|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
% hexdump -C AutoSketch9-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 31 33 03 39 2e 30 08 42 |.......413.9.0.B|
00000010 75 69 6c 64 20 38 38 0a 30 37 2f 30 38 2f 32 30 |uild 88.07/08/20|
00000020 30 34 01 00 00 00 38 00 00 00 00 00 00 00 00 00 |04....8.........|
00000030 00 40 00 00 00 00 00 00 1f 40 00 00 00 00 00 00 |.@.......@......|
00000040 00 00 00 00 00 00 00 00 00 40 00 00 00 00 00 00 |.........@......|
00000050 20 40 00 00 00 00 00 00 00 00 00 00 00 00 00 00 | @..............|
00000060 00 00 02 00 00 00 76 5e 00 00 42 4d 76 5e 00 00 |......v^..BMv^..|
00000070 00 00 00 00 76 00 00 00 28 00 00 00 00 01 00 00 |....v...(.......|
00000080 bc 00 00 00 01 00 04 00 00 00 00 00 00 5e 00 00 |?............^..|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
% hexdump -C AS10-s01.SKF | head
00000000 0a 00 00 00 00 0b 03 34 31 33 04 31 30 2e 30 08 |.......413.10.0.|
00000010 42 75 69 6c 64 20 31 31 0a 31 32 2f 30 32 2f 32 |Build 11.12/02/2|
00000020 30 30 38 01 00 00 00 38 00 00 00 00 00 00 00 00 |008....8........|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000040 00 00 00 25 91 48 24 12 89 30 40 5d 2c 16 8b c5 |...%.H$..0@],..?|
00000050 62 27 40 00 00 00 00 00 00 00 00 00 00 00 00 86 |b'@.............|
00000060 01 36 00 02 00 00 00 76 5e 00 00 42 4d 76 5e 00 |.6.....v^..BMv^.|
00000070 00 00 00 00 00 76 00 00 00 28 00 00 00 00 01 00 |.....v...(......|
00000080 00 bc 00 00 00 01 00 04 00 00 00 00 00 00 5e 00 |.?............^.|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
Version 10 was the final version released of AutoSketch in 2008. It appears the SKF files from version 7 & 8 share the same format and 9 & 10 share one as well. This seems to be confirmed in the save as dialog in version 9 which lumps version 7 & 8 together.
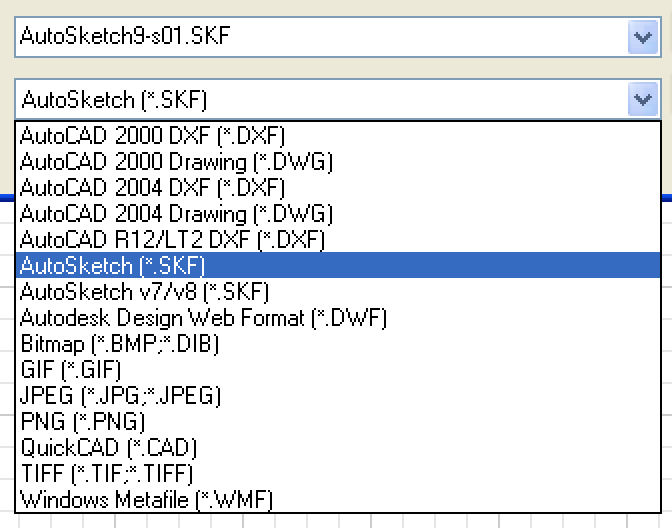
So, if we wanted to make one signature for all SKF files, it might look something like:
0A000000000B0334(30|31)(31|32|33)
Or we can choose to split out versions if needed. For now, adding this signature to the existing PRONOM entry for SKF would be helpful. As for the earlier SKD format, we clearly need two signatures, one for the first version and one for the second.
Here is a small timeline of the different versions of AutoSketch.
AutoSketch Release 1.0 DOS 1986-10
AutoSketch Release 1.01 DOS 1987-02
AutoSketch Release 1.02 DOS 1987-09
AutoSketch Release 1.03 DOS 1988-02
AutoSketch Release 2.0 DOS 1989
AutoSketch Release 3.0 DOS 1990
AutoSketch Release 3.1 DOS 1991
AutoSketch Release 1.0 Windows 1992
AutoSketch Release 2.0 Windows 1994
AutoSketch Release 2.1 Windows 1996
AutoSketch Release 5 Windows 1997-11
AutoSketch Release 6 Windows 1998-10
AutoSketch Release 7 Windows 1999
AutoSketch Release 8 Windows 2001
AutoSketch Release 9 Windows 2004-09-20
AutoSketch Release 10 Windows 2008-11
I need to do a little more research on the DrafixCAD format, but I will update the signature when I do. As always take a look at my samples and suggested signatures on my GitHub page.