Image compression has been around for awhile. It seems everyone took a crack at making better algorithms to improve quality and size. Some chose to invent new ways and others chose to use existing methods but with their own flare. Kodak tried this with their PhotoCD, but there was a couple other photo processing options that popped up in 90’s. One was Seattle FilmWorks and another was Konica PC PictureShow. Both of which used “proprietary” formats to deliver developed film on disk.
Seattle FilmWorks later called PhotoWorks, used an image format with the extension SFW and was based on BMP and JPG, but with their own twist. The same goes for the format used by Konica’s PC PictureShow.
If you took your film in to be developed at one of Konica’s photo labs, you could could have those images put on a diskette or later a CD-R. The disks came with software to view your photos called PC PhotoShow. The images stored on disk where in another proprietary format with the extension KQP. The KQP format was actually licensed from another company called Pegasus Imaging Corporation, later known as Accusoft. They developed their own way to compress a JPEG file which they called an ePic. An SDK called PICTools was offered for many years, but seems not to be available anymore.
ePIC (Proprietary)
Supports PIC format compression, replacing the JPEG Huffman encoder with the proprietary ELS entropy encoder for 15% more compression.
Can be losslessly converted back to JPEG format using Op_RORE.
A search on the internet for Konica KQP shows quite a few people over the years wondering what to do with their old disks and converting the old format to JPG, only to find a lack of information and available tools to do so. One such person used python to edit the file and making the file renderable as a JPG. While the method worked well for their KQP files, it might not work for all of them. Let’s look closer and understand why.
At first glance the file appears to be a Bitmap (BMP), and it does have a Bitmap header claiming to have JPEG compression, but if we look a little further into the file.
identify -verbose Sample.PIC identify: length and filesize do not match `Sample.PIC' @ error/bmp.c/ReadBMPImage/950. identify: unrecognized compression `Sample.PIC' @ error/bmp.c/ReadBMPImage/1019.
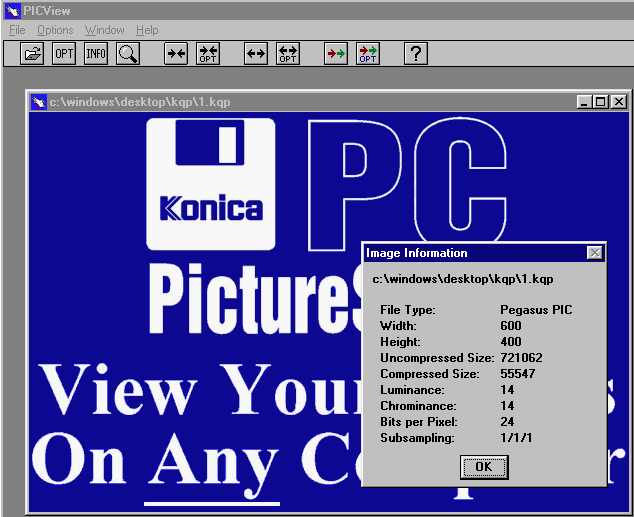
We find a JPG marker, in fact almost the whole jpg file is included, except the quantization tables for luminance and chrominance which are needed to properly display the image. This is the area the Pegasus company thought they could encode better to further compress the image. Their method was to use a new algorithm called ELS (Entropy Logarithmic-Scale). This new method was used by the PICTools software to make a Pegasus PIC file while Konica used it for their KQP format. They are identical. By choosing the luminance and chrominance values during compression, you could make a highly compressed image, but required specific software to render.
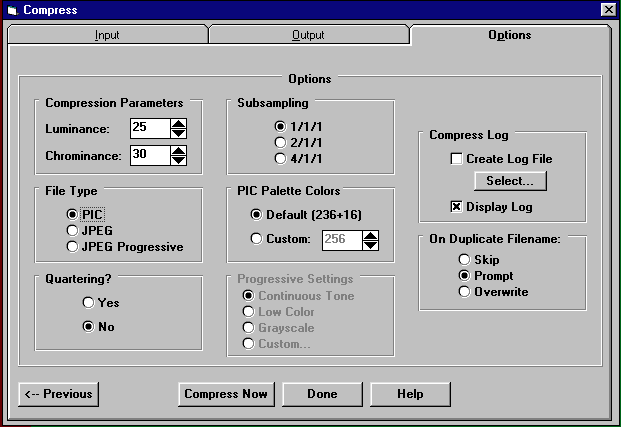
Pegasus also made use of a special custom APP marker (PIC) within the JPEG structure of the PIC/KQP and also any JPG compressed using their software. This marker which takes up around 8 bytes holds the luminance and chrominance values. Take the above sample for instance, it is compressing the image with a Luminance of 25 and a Chrominance of 30, these are integer values and in hex they would be “19” and “1E” respectively.
So in theory one could strip out any part of the file before the JPG beginning of file magic bytes (FF D8 FF E0), locate the APP marker, use the values to generate the two quantization tables, insert them in the appropriate spot and save out a JPG file.
This may be the case for the first few versions of the ePic format, but later versions got more complicated. It seems a “PIC2” version replaced the earlier versions and this format is a little more complicated.
Instead of the Bitmap (BMP) header, a proprietary PIC2 header is used, still containing a JPG in the JFIF format along with a the PIC APP marker, but encoded in a way that the simple method of adding a quantization table may not work. With the original format the JPG and the PIC/KQP were approximately the same size, this new version significantly reduces the size of the PIC/KQP in comparison with the JPG.
The ELS compression technology used in the ePic format seems to be patented by Pegasus and Accusoft, but is not entirely hidden as the libavcodec library includes a ELS decoder. Might be a fun project to use the code to decode the PIC/KQP formats fully.
In the meantime, a signature identifying the two versions should be added to PRONOM. Check out my proposal on my GitHub. If you need to convert your KQP or PIC files back to JPG here are a few links:
There seems to be a never ending source of file formats out there. Documenting past obsolete formats, one would assume a point at which there are no more to find, but in reality more are re-discovered everyday by the Digital Preservation community. When it comes to more modern formats, it seems more are invented everyday, too many to keep up with identification. Document one, 10 more pop up, it seems never-ending. Such is the case for scientific formats, including sequencing formats.
I was speaking with a colleague from another institution the other day and a file format was mentioned I hadn’t heard of before. It seems many of their scientific data was stored in a format called FASTA “Fast A” (“fast-aye”). This format specifically stores DNA sequence data and is used quite a bit, it seems. I was even more surprised the next day when I went to process some new submissions for our repository only to find one submission contained three FASTA files. I love researching file formats, but sometimes in order to understand the format structure you have to know something about the content as well. Let’s explore the FASTA and FASTQ file formats. If you would like to take a peek at the Human Genome in FASTA, go here.
Both the FASTA and FASTQ formats are text based and have a simple structure. Identification of each of these should be pretty simple, but to avoid conflicts with other formats, the signature might have to be more complex.
The FASTA format is well documented as many in the scientific community use it. Basically the format starts with the greater than “>” character followed by a description, a new line character, then the sequence. For example:
>MCHU - Calmodulin - Human, rabbit, bovine, rat, and chicken MADQLTEEQIAEFKEAFSLFDKDGDGTITTKELGTVMRSLGQNPTEAELQDMINEVDADGNGTID FPEFLTMMARKMKDTDSEEEIREAFRVFDKDGNGYISAAELRHVMTNLGEKLTDEEVDEMIREA DIDGDGQVNYEEFVQMMTAK*
Pretty straight forward, but so much of the format can be variable, a simple signature would clash with too many other formats. There are some rules with what characters can be used in the sequence so it might be possible to limit the signature to only allow certain characters. At first I thought it might only be able to contain the standard characters representative of adenine (A), cytosine (C), guanine (G), and thymine (T), but as it turns out the FASTA format can contain Nucleic Acid Code’s and Amino Acid Code’s. These codes allow more than the four I was expecting, but do limit what can be represented.
Instead of a greater than symbol, the FASTQ format uses an “@” symbol followed by an identifier. The identifier can be basically anything and as long as needed. There is a newline character followed by the DNA sequence, which is only the four characters I have heard before. It can contain an A, C, G, T, or N. The “N” can represent an unidentified nucleotide or indicate that the software was unable to make a basecall. A newline character again and the “+” symbol. This is place before the fourth line with is a quality score and is the same number of characters as the sequence.
See what I mean when you have to learn about the context of a format in order to make a proper signature!
One of the problems I am left with is how to determine how many of the sequence characters to use in the signature to not have any conflicts. Too few and it might conflict with another format or simple text file. Too many and the signature gets complicated and may exclude a short sequence file. As far as I can tell there is no set minimum or maximum for the sequence. Not sure what the genome for Pinus Taeda would look like in FASTA with 22.18 billion base pairs. The other problem is often times these formats are compressed into a GZIP file, so they need to be extracted before identification.
These two formats are just a couple of the many sequencing formats being used in the bioinformatics community. I am sure others will pop up in the future. Until then, I have with the help of others put together a signature which seems to work well for the samples and data sets we have access to. Take a look at my GitHub for the signature proposal. If you find any issues, let me know!
I have used and have researched a lot of audio editing software. Some are very simple and straightforward, others are feature rich and take some time to learn. While looking in a format, I came across some Audio software which nothing like I have used before. At first I was confused, I figured it would be simple to open a certain file format and play the audio. Not so fast.
Max is software which proudly says it is an, “infinitely flexible space to create your own interactive software”. Created by Cycling ’74 software, Max has been around for awhile, being developed in the mid 1980’s. It allows the user to make “patches” stringing around components and effects to accomplish an infinite amount of options and outcomes.
The software produces simple project files and patch files, but hey are just JSON data, at least in the latest version. But when working with audio files the software can save to a number of formats.
One of the options is a format called “SDIF”, which stands for “Sound Description Interchange Format“. SDIF was jointly developed by IRCAM and CNMAT, with proposals starting back in the mid-1990’s. Originally written as a Spectral Description, it was later changed to refer to a Sound Description.
The Specification states the general idea was to “store information related to signal processing and specifically of sound, in files, according to a common format to all data types. Thus, it is possible to store results or parameters of analyses, syntheses…” So not exactly the same as a simple WAVE file you can open and edit, this format was meant to store signal data for analysis.
Each SDIF file consists of a header and then an overall a succession of frames, not unlike chunks in the IFF/AIFF/RIFF formats, ordered in time. Each frame matrix declares a “Type” which can be a combination of many options. Lets take a look at a SDIF file:
This test file has the opening frame “SDIF“, to identify it as an SDIF, then a reference to the type “1TRC“. I would try and explain a Matrix 1TRC Sinusoidal Track, but I have no idea what it means. Something, something sine wave, etc. Someone much smarter than me can make use of this format. Here are a couple examples of SDIF with other frame types.
Unfortunately, the common tools I use to explore AV formats don’t seem to work on this format. MediaInfo, FFProbe, Exiftool, all give me unknown file warnings. So I had to compile the SDIF software in order to get some details.
querysdif angry_cat.part.sdif Header info of file angry_cat.part.sdif:
Data in file angry_cat.part.sdif (9504872 bytes): 1933 1TRC frames in stream 0 between time 0.000000 and 5.794875 containing 1933 1TRC matrices with 45 --400 rows, 4 -- 4 columns
An interesting thing is that a SDIF file can be in text form as well.
An interesting format for sure. But wait, there is more!
My initial interest in this format was when I was given access to a set of MUBU files. I was unclear on how there were created at first and it took me down a long path of learning about SDIF and the Max software from Cycling ’74 and IRCAM. MUBU turns out to be a toolbox for Max which adds more analysis features.
MUBU stands for MUlti-BUffer, which helps overcome some limitations. It is actually a container using the SDIF standard. Lets take a look.
hexdump -C test.mubu | head 00000000 53 44 49 46 00 00 00 08 00 00 00 03 00 00 00 01 |SDIF............| 00000010 31 4e 56 54 00 00 00 78 ff ef ff ff ff ff ff ff |1NVT...x........| 00000020 ff ff ff fd 00 00 00 01 31 4e 56 54 00 00 03 01 |........1NVT....| 00000030 00 00 00 53 00 00 00 01 4d 75 42 75 2e 43 6f 6e |...S....MuBu.Con| 00000040 74 61 69 6e 65 72 2e 4e 75 6d 54 72 61 63 6b 73 |tainer.NumTracks| 00000050 09 31 0a 4d 75 42 75 2e 43 6f 6e 74 61 69 6e 65 |.1.MuBu.Containe| 00000060 72 2e 56 65 72 73 69 6f 6e 09 31 2e 35 0a 4d 75 |r.Version.1.5.Mu| 00000070 42 75 2e 43 6f 6e 74 61 69 6e 65 72 2e 4e 75 6d |Bu.Container.Num| 00000080 42 75 66 66 65 72 73 09 31 0a 00 00 00 00 00 00 |Buffers.1.......| 00000090 31 4e 56 54 00 00 00 38 ff ef ff ff ff ff ff ff |1NVT...8........|
A MUBU file has the same SDIF frame header, but also include a “1NVT” frame, which is a Name Value Table. This is where the MUBU container is referenced. The MuBu file has its own structure:
If I query the MuBu file like I did the SDIF, I get the following:
querysdif test.mubu Header info of file test.mubu:
Data in file test.mubu (3741392 bytes): 77929 M000 frames in stream 0 between time 0.000000 and 1.623500 containing 77929 M000 matrices with 2 -- 2 rows, 1 -- 1 columns
The MuBu file contains one audio track and one buffer. This is a simple test file, but MuBu files can be quite large with multiple tracks.
Working with the Max software or OpenMusic is not something I found to be easy to understand. I am sure if I was more musically inclined and with a little practice I could make some of this work. For the time being, a signature to identify a SDIF and MUBU will have to do. Check out the GitHub for my proposed signature and a couple examples.
Music notation software is among the earliest software for desktop computers. SCORE in 1987, Finale came around in 1988, Capella in 1992, and Sibelius in 1993. Many others came and went during this time. Music notation software was so much more than the typical word processing or desktop publishing system. Specialized fonts were needed to display the music notation and there are many other variables for different instruments allowing individuals and others the ability to create complicated compositions in an inexpensive way.
Sibelius[SI] + [BAY] + [LEE] + [UHS] was originally developed for the Acorn system in 1986, then released on Windows and Macintosh in 1998-99. The software became very popular and in 2006 was purchased by the software giant AVID. The software was used enough to get a preservation assessment by the British Library in 2017 and draft status format description by the Library of Congress, written by the amazing Ashley!
Both reviews of the format emphasize the proprietary nature of the file format which has been used since the early versions. Aside from the early Acorn release, the Windows and Macintosh versions used a binary format with the SIB extension. They are actually quite easy to identify.
This is exactly how PRONOM and other identification methods determine they are Sibelius files. PRONOM has assigned the format fmt/696 and is looking for the hexadecimal bytes 0F534942454C495553.
The problem with this identification method is that all the Sibelius files are identified as such, regardless of version. As mentioned by Ashley, version of the software used is highly important as new features were added all the time making backwards compatibility difficult. Add in the fact that there were different releases for each version which would limit these features even more and I can see how a musician could get very frustrated. If you created a score in Sibelius 5 and tried to open in Sibelius 5 Student version, you may find your composition lacking in many ways. The only way to avoid compatibility issues is to always open in the latest “Ultimate” version. Sibelius Ultimate can open all versions of the SIB format back to version 2. The software even has an export feature which allows you to export back to a previous version stripping what is necessary to ensure compatibility.
For those with a bunch of SIB files in their archives, how would you know which software version created the file? Well lets take a closer look at the bytes and see if we can find some patterns. Let it be known, I am not reverse engineering the format, just looking for patterns which will allow for proper identification!
I am not the first person to ask this question, many others want to know the versions of their SIB files. Thankfully others have found some clues on which bytes hold the version information. It seems we can determine the version based on 4 bytes shortly after the SIBELIUS string. Specifically bytes 10-13.
That is a lot of versions and I feel there may be some gaps that still need to be identified. It appears that the first two bytes are the major version and the second set of bytes is the minor version. Although it looks like a few major version bytes span across a few software versions. With this chart, one could be very specific in identifying which Sibelius version wrote the file, but for archiving purposes it seems we can group many of these capturing just the major version. The export screenshot above seems to have broken down significant changes and grouped similar formats together, the biggest being 8.6 through 2019.12. A comparison of “student” and “first” formats don’t have any obvious bytes which indicate as such, so for now they are all lumped together.
There is one other similar format which needs to be mentioned. Sibelius Scorch was a product made to share scores online. This has been replaced with Sibelius Cloud Publishing, but for awhile was the best way to share a score with others in a way that protected the original. I have no idea how they were made, but sites like scorestreet.net and sibeliusmusic.com were sites you could upload your score to for sharing. Some SCO files appear to have a PDF embedded within them for proper printing.
I am not sure the best way to handle all the different versions within the PRONOM registry. I went ahead and made a few signatures based on the export dialog of Sibelius 2024. Even with combining a few together, it leaves us with 17 new PUID’s. Maybe further discussion can refine these down a bit more? Regardless, each file can be associated with a specific Sibelius version, making it easier to open and migrate if needed without fear of opening in the wrong version. Take a look at some samples and my signatures on my GitHub page and let me know if there is a better way.
I was recently going through some of my old CD-R’s and came across this 11 year old fun memory.
I remember going to this 2003 Toad the Wet Sprocket concert in Salt Lake City with some friends, I had seen this band perform before, but this was the first time I was able to get a recording of the show. Normally having a recording of a concert of a well known band was a little shady, but for some bands, they not only allow recording of their live concerts, but they encourage it. There has been a few bands over the years who have this philosophy, one most have heard of is the Grateful Dead, because of all the tape trading, the band’s numerous concerts will live on forever.
The scene of recording concerts is still alive and well, and if you are into recording and sharing it is expected you share in a lossless audio format. The world of lossless audio is definitely in the minority of all those who listen to music on the daily. Most of us have been placated with the infinite playlists on services like Apple Music, Spotify, and Amazon Music. Most probably don’t care about owning music anymore, but for the few who consider themselves Audiophiles, having a lossless audio file is the only choice.
When it comes to formats, there are a few lossless formats to choose from, they all come with some advantages as well as some downsides. WAV files contain the full PCM audio stream, and while internet bandwidth today can handle full uncompressed audio, it can still be beneficial to use some compression for archiving or sharing over the web.
The most common lossless format today is the Free Lossless Audio Codec or FLAC, but there are also quite a few who like the Apple Lossless Audio Codec. Both offer many advantages, especially with metadata, cuesheets, and can contain cover album art. But many years ago another lossless format was most often used with bootleg recordings and audio sharing.
Shorten was one of the first lossless formats, developed by Tony Robinson in 1993 for SoftSound. It could cut the size in half of a typical 16-bit WAV file. It achieved this by using Huffman coding, kinda the same way a JPEG works, by reducing the frequency of how often patterns occur. Today FLAC and ALAC have replaced this format and offer improved features and support. Many audio players have dropped support for shorten making it difficult to use this old format.
The Shorten format uses the .SHN extension. It is one of the formats listed on the Library of Congress Sustainability of Digital Formats with the ID fdd000199, although a couple links don’t appear to work as it hasn’t been updated since 2011. Support was ended for this format and many of the links found on various websites are for broken, usually referencing the etree wiki. Much of which is archived on the Internet Archive.
Let’s take a look at the what makes up a lossless compressed SHN file. A quick look at a sample header:
The first four bytes seem to be consistent among my samples. It makes me wonder if the ascii values have something to do with the author, Anthony (Tony) J. Robinson. In the source code for the shorten software, the file shorten.h defines the ascii “ajkg” as the magic header for the SHN format. Also found in current ffmpeg code. Although the tools don’t have much to say about them.
mediainfo test.shn
General
Complete name : test.shn
Format : Shorten
Format version : 2
File size : 3.17 MiB
Audio
Format : Shorten
Compression mode : Lossless
ffprobe -i test.shn
Input #0, shn, from 'test.shn':
Duration: N/A, start: 0.000000, bitrate: N/A
Stream #0:0: Audio: shorten, 44100 Hz, 2 channels, s16p
Using the older SHNTOOL, we can get more information.
shntool info test.shn
-------------------------------------------------------------------------------
File name: test.shn
Handled by: shn format module
Length: 0:32.23
WAVE format: 0x0001 (Microsoft PCM)
Channels: 2
Bits/sample: 16
Samples/sec: 44100
Average bytes/sec: 176400
Rate (calculated): 176400
Block align: 4
Header size: 44 bytes
Data size: 5697720 bytes
Chunk size: 5697756 bytes
Total size (chunk size + 8): 5697764 bytes
Actual file size: 3325489
File is compressed: yes
Compression ratio: 0.5836
CD-quality properties:
CD quality: yes
Cut on sector boundary: no
Sector misalignment: 1176 bytes
Long enough to be burned: yes
WAVE properties:
Non-canonical header: no
Extra RIFF chunks: no
Possible problems:
File contains ID3v2 tag: no
Data chunk block-aligned: yes
Inconsistent header: no
File probably truncated: unknown
Junk appended to file: unknown
Odd data size has pad byte: n/a
Extra shn-specific info:
Seekable: yes
Many Shorten Audio Files are found out there in archives and file sharing sites, so even though the format isn’t used to create new files, it will still be around for awhile. My GitHub has my signature proposal and a couple of samples.
When it comes to design software there were many options over the years, many being released with a lot of hype and others disappearing not long after they released. There are few which lasted long enough to not be gobbled up by big names such as Adobe. One of those is Canvas by Deneba Systems.
First released in 1987, it is still available over at Canvas GFX. It’s amazing it was never bought by one of the big names, Adobe, Corel, Aldus, etc and remained under Deneba Systems until 2003 when it was bought by ACD Systems, but kept the name Deneba Canvas for a time. The later versions were not popular to all, and Mac support was dropped, but the software continued. Awhile back I was looking through a few of my old ZIP disks and found some software my father used in the mid 1980’s. He had a copy of Canvas version 2 for Macintosh. At that time I was more interested in playing games on our family’s Macintosh 128k than using design software.
Over the years I have come across many Canvas documents. With each version released, changes were made to the file format used to store the drawings and artwork. There were many file format changes as well as the extensions used with each version. Some are easily identifiable and others have some confusing structures. Lets look into it.
Version
Platform
Extension
Description
Canvas 1-3 & artWORKS
Macintosh
none
no strong pattern
Canvas 3.5
Mac & Windows
CVS
Similar to v1-3
Canvas 5
Mac & Windows
CV5
CANVAS5 string
Canvas 6-8
Mac & Windows
CNV
CANVAS6 string
Canvas 9-X
Mac & Windows
CVX
Similar to 6-8
Canvas Draw
Mac
CVD
Different than others
Canvas Image File
CVI
DAD5PROX
The first three versions of Canvas were Macintosh only and in those early days there was no extension, just a Type / Creator indicating to the Finder how to open them. Deneba Systems used the Creator codes DAD2, DAD5, through DADX.
The first versions are quite frustrating. I have gathered samples from Version 2, 3, 3.5 and artWORKS version 1. Even with numerous samples, there are no patterns I can discern from them. I even reached out to the current CanvasX technical support for answers. They wanted to be helpful, but their answers didn’t offer much help.
With “CVS” or ‘drw2’ for mac, the header contains ranges inside a structure, and other data like if it was compressed. When we see if it’s a valid file we check the ranges. There is no easy way to determine what hex values would be written because of flipping, Intel vs (PPC or 68K). Unfortunately, the research needed to identify the Hex value will require the original code for version 3.5 which we do not have access to easily. Canvas 3.5 code is 16 bit… this would also be an issue.
In the version 2 & 3 samples you can see some patterns, which I thought would allow for proper identification, but looking at more samples I found differences. One pattern I was hopeful might be consistent was the hex values “002000400060008000C00140018001C002400280”, but there are some which don’t match this pattern. If the file is truly compressed, it will be hard to know which values would be consistent among all files. I have over 8,000 samples and have a signature that only excludes around 20, so it will have to do for now.
When we start with Version 5 we get into some more identifiable headers, there is some oddness with some samples. But with an ascii string like “CANVAS5”, it should be easy, right? Not so fast, in version 5 you can compress the file structure. This removes the easily identifiable “CANVAS5” string. But some have a small string at the tail end, but others do not.
Canvas 6 uses a new extension, but has a similar structure to the file format. With compression as an option. But some of the compressed files on Windows has a reversed string, “5VNC“. So many Canvas 5 compressed look identical to Canvas 6 compressed, complicating identification.
While most have the “CANVAS6” string near the beginning, quite a few are missing the CNV5/5VNC string at the end. Instead, many have the string “%SI-0200” near the end, which I use in my signature suggestion. This structure remained the same from version 6 to 8.
In version 9 and forward we have an extension change to CVX, but the format is similar with the “CANVAS6” string, but is a slightly different offset. It is still used with the current version of Canvas X.
This collection of file formats is very hard to make sense of. Some really great consistent patterns on many samples, with lots of exceptions. Super confusing. This software has had a long run, with the latter years staying pretty stagnate in terms of new development. It is worth defining and creating a signature for the consistent patterns, then we can dial in the variants over time?
The signatures I have built miss about 23 files in versions 1-3 out of the ~9000 samples I have and for Canvas 5, only some of the compressed files are currently not identified. But so far all my CNV and CVX files identify correctly, so probably good for now.
CanvasX dropped supported for the Macintosh, but did release an entirely different product called Canvas X Draw, which does support the Macintosh. Here is what a CVD file looks like:
There is also the matter of a Canvas Image, which the User Guide calls proxy images. They are Raster images used in placements within Canvas Documents. Should be easy to identify.
Phew, if you held on for this whole post you must really like confusing file format structures. This format has been on my mind on and off for about 6 years. Hopefully these signatures will work for the vast majority of the Canvas files found in archives and personal systems. As always here is my GitHub with the signatures I am proposing and a few samples to get you confused.
There are probably many reasons why a software developer might want to create a proprietary format to store their files in. The software may require special features that don’t fit into an existing format. I would hope a developer would try to use existing formats, or even better open formats, but for many reasons, which probably include profits, they choose to re-invent the wheel often.
MAGIX is a German company which started making software in 1994. In 2001 they developed their first video editing software which was called Movie Edit Pro. The software seems to be well received and is still in use today.
Like most video editing software, project files are used to store all the edits and links to video files. These are usually smaller text based, with many using XML as the project format. Not MAGIX, they decided to go with a different yet known format for their project files.
Yes, they used the RIFF container format for their projects. Seems an odd choice, especially for video production although it is well suited for it. AVI is another video format which uses the RIFF container. The MVP project file uses the ID SEKD with the format MVPH. Earlier versions of Movie Edit Pro used a different extension.
The MVD format used on an earlier version of Movie Edit Pro is also a RIFF, and with the ID of SEKD, but has a format of SVIP.
RIFFpad can break down the chunks we see in an MVP file. Each of the LIST chunks has their own subchunks as well. I assume this his how the editing software stores each video/audio track references, etc. So I give it to MAGIX for at least using an understandable format to store their projects.
MAGIX has also used RIFF in many of its supporting formats. So far I have found mfx, afx, ifx, cfx, ctf, tfx, ufx, mmt, mmm, hdp, each having their own format:
Not sure the best way to manage all of these in terms of identification, as I am not sure what what is the purpose of each format. Maybe for now I’ll make a generic to catch them all as a MAGIX File.
Extension
ID
FORMAT
AFX
SEKD
SAFX
CFX
SEKD
SCFX
CTF
SEKD
SVIP
HDP
SEKD
SHDP
IFX
SEKD
SIFX
MFX
SEKD
MAFX
MMM
SEKD
SVIP
MMT
SEKD
SVIP
MVD
SEKD
SVIP
MVP
SEKD
MVPH
MXM
MXMD
mxmi
TFX
SEKD
STFX
UFX
SEKD
SVIP
But, when it comes to their proprietary MAGIX Video format, I think they may have pushed things a little too far. Meet the MXV format:
I am not sure what I am looking at, is it a RIFF? Is it a RIFF variant like RF64? MAGIX claims the format is:
This is the MAGIX video format for quicker processing with MAGIX products. It offers very low loss of quality, but it cannot be played via conventional DVD players.
A look around the internet doesn’t bring much up in reference to this format. Just my recent page on the format wiki. A search for MXRIFF64 bring up nothing. But a closer look at other strings within the MXV file reveal we are probably looking at some sort of MPEG format.
I was able to locate a project on GitHub which claims to be able to demux the MXV format. The software is written in GO and appears to indicate this format is chunked based and has most of the chunks figured out. So if you find yourself stuck with some MXV files and don’t want to use the latest from MAGIX, this might be the tool for you.
This demuxer also has an interesting file you can download. It is called a “GRAMMAR” file and can be loaded into hex viewers like Synalyze It! can show the parts of a file you load. Its a great way to explore a format!
None of these formats are found in PRONOM, project files are not usually kept in archives, but if would be good to know about the RIFF files if they do turn up. The video format is for sure something the archival world should know about. MediaInfo is currently not aware of this format, but seems like it might be an easy task.
As usual, you can see some samples and my proposal signatures on my GitHub.
Many software titles we have all used began life under a different brand or even title. Larger software companies gobble up smaller developers, some brands merge, and others change names for whatever reason. Adobe has bought many smaller companies over the years, sometimes developing the acquired software and other times burying the software to avoid competition. Pagemaker was bought to give InDesign life, many Macromedia titles were incorporated or shelved. Such is life in the software world.
In understanding a file format, often times you need to follow this trail backwards to understand when file formats changed and compatibility is dropped. Often times the formats remained the same, but the extension is changed. Or the software name changes and formats are updated, but the extension remains the same. There can also be multiple titles which all use a common format, further complicating the identification of the formats.
Let’s look closer at the a title which changed names and file formats a few times over the years. Micrografx was founded in 1982 and were pretty well known for their innovation in computer graphics. They have released many titles over the years, but one of the first was In*A*Vision graphic software for Windows 1.0 in 1986. This software used a format with the .PIC extension. A couple years later version 2, was renamed to Micrografx Designer and used the .DRW extension. This extension was also used by Micrografx Draw, another similar program.
Micrografx Designer continued to be released until version 9 which is when it was purchased by Corel who continued to release new versions, although it is said the software was just a variation of CorelDraw, and now Designer is part of the CorelDraw Technical Suite. Other Micrografx software such as Picture Publisher was discontinued and customers were encouraged to use Corel’s PaintShop Pro instead. Somewhere in the middle of all this, Micrografx spun off a separate business unit called iGrafx, which Designer was marketed under for a short time.
Let’s break down the names, extensions used, and format type.
In*A*Vision & Draw, binary format, PIC extension
Micrografx Designer & Draw, binary format, DRW extension
Micrografx Designer version 4, RIFF format, DS4 & MGX extension
Micrografx Designer versions 6-9, OLE Container format, DSF extension
Micrografx/Corel Designer versions 10-12, RIFF format, DES extension
Corel Designer version X4-Current, ZIP/XML format, DES extension
You can import Corel DESIGNER files. Files from version 10 and later have the filename extension .des. Files from Micrografx versions 6 to 9 have the filename extension .dsf. Version 4 files have the filename extension .ds4. The .drw filename extension is used for a Micrografx 2.x or 3.x file. Micrografx template files (DST) are also supported.
The PRONOM registry has a few of these formats with signatures and documented, but not all, let’s see where the gaps are.
So from the PRONOM list, it appears we have good identification on the original PIC and DRW formats. Then the Designer DSF OLE container is taken care of as well. That leaves us with DS4 and DES formats.
Each RIFF format has a four byte identifier type after the first eight bytes which identify the RIFF. The DS4 file uses the code “MGX ” to identify itself. Which also appears to be used with their clipart format, MGX. We can use the same identification method we use for other RIFF’s to identify this format.
Starting with version 10 of Corel Designer, the RIFF format is used again and has a different type. With Version 10 using “DESA”, then for version 10.5:
Looks like the container holds a RIFF inside along with some thumbnails, metadata, and other things. The mimetype file simple holds “application/x-vnd.corel.designer.document+zip”. The riffData.cdr however looks like this:
Another RIFF, and seems to be in the same sequence, but going from version 12 to X4 we seemed to have skipped “DESD”. Maybe there was a developer version in between as they transitioned. Version X5 looks similar and has the RIFF sequence “DESF”. When we get to X6 the structure changes.
The mimetype remains the same, but we see additional files within the structure. Also the riffData.cdr file is missing. Looking at each file we can see the root.dat file is a RIFF and follows the same sequence.
The last sample I have is for Corel Designer 2022, but there could be more. I created new signatures for all the samples I have, you can see them in my Github as usual. I decided to group some of the versions together to simplify things a bit, but if anyone thinks they should be broken out into individual versions, let me know.
In honor of #Marchintosh, I threatened in an earlier post to discuss The Writing Center, one of the many writing programs marketed by the Learning Company for the Mac. This one was developed by Datapak Software, Inc and I think they wanted to watch the world burn.
This format was different enough from the Student Writing Center and the “Ultimate Writing & Creativity Center” to need its own post. Moreover, I am pretty sure the developers of this software were actively trying to frustrate anyone trying to document the format. Let me explain.
In the early Macintosh world, very rarely were extensions used. Current systems use extensions to link the file to an application which can open the file. On the Mac, the system would use special attributes called Type / Creator codes. These codes were registered with Apple so they would be unique to a specific software and type of file. The codes used the FourCC system and unfortunately Apple never released a full list of codes used. Some folks over the years have tried to document as many as they can. Many used simple understandable codes, for example, A Microsoft Word document has a Type / Creator of W6BN / MSWD. The creator code of MSWD is very readable, and the type code W6BN is unique to a document from version 6 of Microsoft Word.
This Sample Report file from The Writing Center, when investigated with the ResEdit tool show interesting Type / Creator codes. If we look at the hexadecimals values for the codes. The first four bytes are the Type code and the second set of 4 bytes are the Creator code.
The first thing to know is the encoding for all Type / Creator codes is MacRoman, so if we look up the hexadecimal code for “0A” we learn it is the character for a new Line Feed, why in the world would you use the line feed character? The developers must have had a sense of humor, or are psychopaths, and I’m leaning toward the latter. Trying to put this character into any sort of spreadsheet or text based document with other codes throws everything off! When I try and use a spreadsheet with a group of codes and then use a script to look them up on the command line I get crazy formatting. Not to mentioned the second character in the creator code is “1A” which is a substitute character.
This is just one example of crazy characters being used in Type / Creator codes. Stay tuned for more on these in future discussions.
Even though the Type / Creator codes are very useful in identification of this format, often times the Finder attribute is lost. This can happen if the file is moved off an HFS disk, usually a network or through the internet. Then all we have is the binary data fork and a file with no extension. So finding a signature to identify this format is useful.
Looking at the hexadecimal values of the header of a couple samples doesn’t initially look promising, the first few bytes are very different meaning there is no magic bytes at the beginning of the file. In fact the only thing the same is the mention of the Geneva font used in the document. Looking further into the files.
The only bytes I could find near the beginning that seemed semi consistent is the highlighted bytes above. I did however notice some consistent bytes at the end of each of the files.
The four bytes at the end of each file by themselves would not be a good signature as there are many formats which end with a few “FF” sequences. But maybe combined with bytes near the beginning, a signature might be found. I added a couple samples to my Github page if you would like to take a look. In order to retain the extended attributes, I encoded the files as MacBinary.
lsar -L "Sample Report.bin"
Sample Report.bin: MacBinary
Sample Report:
Name: Sample Report
Size: 29.4 KB (29,404 bytes)
Compressed size: 29.4 KB (29,440 bytes)
Last modified: Thursday, July 25, 1991 at 12:58:20 PM
Created: Saturday, October 13, 1990 at 1:10:54 AM
Mac OS type code: ?WP1 (0x0a575031)
Mac OS creator code: ??WP (0x0a1a5750)
Mac OS Finder flags: 0x0100
Index in file: 0
Length of embedded data: 29404
Start of embedded data: 128
Original archive entry: Is an embedded MacBinary file: Yes
I think when most of us have some data to sort or make sense of, we tend to gravitate toward a spreadsheet. Using Excel or LibreOffice, or if you really like to party, OpenRefine. There are plenty of meme’s out there representing the frustration people have with bugs, features and limitations of Excel specifically.
Optimist: The glass is ½ full. Pessimist: The glass is ½ empty. Excel: The glass is January 2nd.
There are more tools out there for making sense of data, one some people have access to is Microsoft’s more advanced PowerBI tool. Marketed as a Data Visualization tool it is accessible to many with a Office 365 subscription. It offers expanded features than excel and isn’t as limited in row maximums.
PowerBi was recently the topic of a Code4Lib editorial issue. The writer of an article for their journal posted two PowerBI datasets which a reader later noticed had private data. After some miscommunications and misunderstandings an open letter was drafted and received some support. Code4Lib did release a statement and lessons were learned.
One statement from the Code4Lib staff caught my eye. “The released files were in a proprietary file format, Microsoft Power BI, with which none of the editors have experience.”
We all use tools for our jobs we are most familiar or available to us. No one can be an expert in all file formats. Some us try, but things change so fast it is impossible. But, we can do more in documenting and making formats identifiable through the tools we use for digital preservation. The File Format Wiki and PRONOM have had no mention of Power BI, so let’s change that.
Microsoft Power BI was released in 2011 and has been part of the Microsoft Power Platform. Power BI can gather data from many sources. The software can be accessed in the Office 365 cloud, but also using a Desktop application. In the desktop application, all the data sources and connections are stored in a single file with the extension PBIX. But there are other related formats.
Just like many modern Microsoft formats it is a ZIP container with a mixture of XML and JSON. There is also a DataModel file along with Settings and Connections. A quick peek at some of the contents shows us:
So it looks like the ZIP structure follows the standard for OpenXML packages as it contains a “[Content_Types].xml” file. So using this XML alone would clash with too many other formats. From what I could find the “DataModel” file is what stores the data is more unique to this format, even though the name is pretty generic. Using a string within the file would probably help be more accurate. The “DataModel” file does have unicode double byte strings we can use. “STREAM_STORAGE_SIGNATURE” seems like a unique enough string to use, but it looks like it may not be unique to PBIX. Looks like the “DataModel” file is a Microsoft “MS-XLDM” file format and is a “Spreadsheet Data Model File Format“.
There is a variation to the DataModel file and I am not sure when the standard is used verses this variation, “This backup was created using XPress9 compression”. Not sure if it is versioning or how the file is saved, but they both seem to function correctly.
After a bit of digging it seems like the MS-XLDM format can be found within an XSLX file. I found an example with these datasets. Within an XSLX there can be a found a file “xl/model/item.data” and it has the same structure as DataModel within a PBIX.
Because this file has a different filename and is in a different path, using “DataModel” should keep identification specific to a PBIX file.
The Power BI Report has a template option. This format uses the .PBIT extension and doesn’t contain any data only a template to use with other data. The structure is roughly the same, but doesn’t contain the “DataModel” file, but “DataModelSchema”, which appears to be a JSON file.
The DataModelSchema JSON has some plain text strings which could be used for identification. Later in the file there is a string, “defaultPowerBIDataSourceVersion“.