
I was recently asked to look at a set of files with the extension of .ASK. A quick little search led me to find they belong to AskSam which was a free-form database software often used by researchers and libraries as early as 1985. The first few versions of Access Stored Knowledge via Symbolic Access Method were released for DOS and later Windows. The company askSam Systems disappeared around 2015.
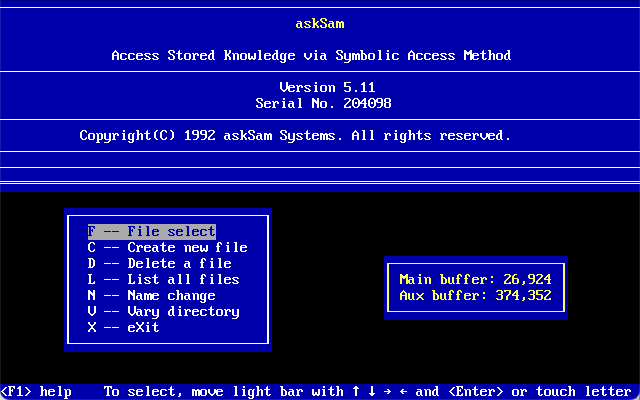
The AskSam software competed with other personal information managers with unstructured data storage and retrieval. It was used to keep track of e-mail, special collections, letters, articles, web sites, etc. It could index all the contents and make searching and retrieval easy. By setting up fields the data could be exported to delimitated text. The software also appears to have been localized in German, but file format is the same.
AskSam had many import filters which included:
- Microsoft Word
- WordPerfect
- Text (ASCII files)
- HTML Files (from the Internet)
- RTF Files (Rich Text Format)
- Eudora E-Mail
- Microsoft Outlook
- Microsoft Outlook Express
- Text delimited files – Comma Separated Values, Fixed position, etc.
- dBASE
- FoxPro
- Paradox
- Microsoft Access
- Microsoft Excel
AskSam has its own proprietary format to store the database using the .ASK extension. They appear to have a 256 byte header. All the DOS versions of the software use the simple BOF string of “askSam”.
hexdump -C TEST.ASK 00000000 61 73 6b 53 61 6d 00 00 00 00 00 07 0f 01 00 00 |askSam..........| 00000010 01 00 00 00 00 01 00 05 00 37 00 02 00 00 00 01 |.........7......| 00000020 33 00 32 00 00 00 00 00 50 00 00 00 00 00 00 00 |3.2.....P.......| 00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000000d0 00 14 00 01 00 00 01 00 00 00 00 00 00 00 00 00 |................| 000000e0 00 00 00 00 00 01 00 00 00 00 03 1d 42 00 01 00 |............B...| 000000f0 00 13 01 00 00 00 00 01 00 00 00 00 00 00 00 00 |................| 00000100 00 00 00 00 f6 00 00 00 00 54 65 73 74 01 01 01 |.........Test...| 00000110 01 01 00
When the first Windows version came out in 1993, the header changed to the logical string:
hexdump -C DOS-WIN.ASK | head 00000000 61 73 6b 77 69 6e 00 00 00 00 00 07 0f 01 00 04 |askwin..........| 00000010 01 00 00 00 01 01 00 05 01 37 03 00 00 00 00 01 |.........7......| 00000020 64 00 32 2e 01 4e 00 00 a0 00 00 00 00 00 00 00 |d.2..N..........| 00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000040 00 00 00 00 00 00 00 00 00 00 00 00 00 76 43 00 |.............vC.| 00000050 00 8c 00 00 00 00 00 00 00 00 00 00 00 01 00 00 |................| 00000060 00 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000070 00 41 72 69 61 6c 00 72 20 4e 65 77 00 00 00 00 |.Arial.r New....| 00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000090 00 00 00 00 00 00 00 00 00 00 5b 3a 00 10 10 10 |..........[:....|
With Version 2 for Windows we start seeing a slightly different header:
hexdump -C AS2W-S01.ASK 00000000 61 73 6b 57 69 53 00 00 00 00 00 07 0f 01 00 04 |askWiS..........| 00000010 01 00 00 00 01 01 00 05 00 37 03 00 00 00 00 01 |.........7......| 00000020 c8 00 32 2f 02 4c 00 00 a0 00 00 00 00 00 00 00 |..2/.L..........| 00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000070 00 43 6f 75 72 69 65 72 20 4e 65 77 00 00 00 00 |.Courier New....| 00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000090 00 00 00 00 00 00 00 00 00 00 5b 3a 00 10 10 14 |..........[:....| 000000a0 14 02 00 00 0a 00 00 00 00 00 00 00 00 00 00 00 |................| 000000b0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 000000c0 00 00 00 00 00 00 00 00 00 00 00 60 00 00 00 00 |...........`....| 000000d0 05 00 00 00 00 00 01 00 00 00 00 00 00 00 00 00 |................| 000000e0 00 00 00 00 00 01 00 00 00 00 00 00 00 00 01 00 |................| 000000f0 00 1d 01 00 00 00 00 01 00 00 00 00 00 00 0a 00 |................| 00000100 00 00 00 00 f6 00 00 00 0a 54 65 73 74 69 6e 67 |.........Testing| 00000110 20 20 00 0a 01 09 10 c0 14 14 42 07 01 | ........B..|
Then all samples from version 4 to the final version 7 all have the same header, although I know there is some features in the later versions that make them incompatible, there isn’t a easy way to identify the different versions after version 4.
hexdump -C Asksam4-s01.ask | head
00000000 61 73 6b 77 34 30 00 00 00 00 25 00 00 00 00 00 |askw40....%.....|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000000f0 00 00 00 00 00 00 00 00 00 00 02 00 00 00 e5 38 |...............8|
00000100 0c 3a 67 31 4d 38 dd b5 9c 65 00 00 00 00 90 01 |.:g1M8...e......|
00000110 00 00 01 01 0c 43 00 00 00 00 00 00 be 00 00 00 |.....C..........|
00000120 24 14 00 00 00 00 00 00 10 14 00 00 00 00 00 00 |$...............|
00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000150 7b 4c 00 00 00 00 00 00 af 4f 00 00 00 00 00 00 |{L.......O......|
hexdump -C AskSam6-s01.ask | head
00000000 61 73 6b 77 34 30 00 00 00 00 38 00 00 00 00 00 |askw40....8.....|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000000f0 00 00 00 00 00 00 00 00 00 00 02 00 00 00 21 f1 |..............!.|
00000100 ad 41 61 9f c0 39 cd 4a af 65 00 00 00 00 58 02 |.Aa..9.J.e....X.|
00000110 00 00 01 01 84 2e 00 00 00 00 00 00 be 00 00 00 |................|
00000120 24 14 00 00 00 00 00 00 50 13 00 00 00 00 00 00 |$.......P.......|
00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000140 00 00 00 00 00 00 00 00 00 00 00 00 c6 5b 00 00 |.............[..|
00000150 ba 33 00 00 00 00 00 00 53 33 00 00 00 00 00 00 |.3......S3......|
hexdump -C AskSam7-s01.ask | head
00000000 61 73 6b 77 34 30 00 00 00 00 87 04 00 00 00 00 |askw40..........|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000000f0 00 00 00 00 00 00 00 00 00 00 02 00 00 00 b2 fd |................|
00000100 b5 47 61 9f c0 39 5c 4b af 65 00 00 00 00 bc 02 |.Ga..9\K.e......|
00000110 00 00 01 01 db 34 00 00 00 00 00 00 be 00 00 00 |.....4..........|
00000120 24 14 00 00 00 00 00 00 50 13 00 00 00 00 00 00 |$.......P.......|
00000130 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000150 aa 39 00 00 00 00 00 00 de 3c 00 00 00 00 00 00 |.9.......<......|
Even though everything after version 4 for Windows has the same header, files created in version 7 will not open in version 6. There must be some additional byte sequences which identify the files with the version which created the file. I have been unable to located the free askSam 7 viewer, but here is a link to the version 6 free viewer. It runs in the latest Windows OS. If you open an older version it will ask you to upgrade your file, so be sure to keep a copy of your original.
Once you have your ASK Database opened, you can export to a few formats, an RTF or a delimitated text file based on fields you have entered in the form. Word of warning, if you entered a password to protect modifying of your data in an earlier version, you have to re-enter the password in order to open/upgrade the file, but the viewer will not open password protected files, you will need the full version.
Here are two files created in AskSam 5.11 DOS, one without a password one with. You can see the 16 byte hex values from offset 41 to 57 are zeros in the file with no password and full of values in the protected file. I’m sure someone with more skills could figure out the encryption.
hexdump -C AS5-OPEN.ASK 00000000 61 73 6b 53 61 6d 00 00 00 00 00 07 0f 01 00 00 |askSam..........| 00000010 01 00 00 00 00 01 00 05 00 37 00 02 00 00 00 01 |.........7......| 00000020 33 00 32 00 00 00 00 00 50 00 00 00 00 00 00 00 |3.2.....P.......| 00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 000000d0 00 14 00 01 00 00 01 00 00 00 00 00 00 00 00 00 |................| 000000e0 00 00 00 00 00 01 00 00 00 00 03 1d 42 00 01 00 |............B...| 000000f0 00 13 01 00 00 00 00 01 00 00 00 00 00 00 00 00 |................| 00000100 00 00 00 00 f6 00 00 00 00 54 65 73 74 69 6e 67 |.........Testing| 00000110 01 01 00 |...| hexdump -C AS5-PASS.ASK 00000000 61 73 6b 53 61 6d 00 00 01 00 00 07 0f 01 00 00 |askSam..........| 00000010 01 00 00 00 00 01 00 05 00 37 00 02 00 00 00 01 |.........7......| 00000020 33 00 32 00 00 00 00 00 50 66 5f 14 66 42 53 40 |3.2.....Pf_.fBS@| 00000030 42 71 29 59 6a 61 62 60 6e 00 00 00 00 00 00 00 |Bq)Yjab`n.......| * 000000d0 00 14 00 01 00 00 01 00 00 00 00 00 00 00 00 00 |................| 000000e0 00 00 00 00 00 01 00 00 00 00 03 1d 42 00 01 00 |............B...| 000000f0 00 13 01 00 00 00 00 01 00 00 00 00 00 00 00 00 |................| 00000100 00 00 00 00 f6 00 00 00 00 54 65 73 74 69 6e 67 |.........Testing| 00000110 01 01 00 |...|
You can check out my samples and my recommendation to PRONOM on my Github page.


















