I wonder sometimes what goes through a software/hardware developers mind when deciding a format to use for a new device. There are so many options our there for audio formats to choose from. I am sure there are pros and cons to using one technology over another but it seems a few decide to go ahead and make their own. I am sure there is some commercial advantage to developing a proprietary audio format, but with all the established choices it seems unnecessary.
Sony developed their own audio compression formats, which I explored in an earlier blog post. I came across a small goofy looking RCA voice recorder, model VR6320.
Many of these RCA VR series recorders can record in a WAV or a VOC file format. The WAV files are pretty run of the mill, but the VOC format is unique to RCA recorders.
The VOC format is not to be confused with another audio format with the same extension. The Creative Voice Format is a bit more well known. It was used with the Creative’s sound cards (Sound Blaster family) many folks had in their Windows computers in the 1990’s. But the RCA file format is different, and because of the same extension needs its own identification so they are not confused with each other.
sf REC00001.VOC
---
siegfried : 1.10.1
scandate : 2023-11-19T23:33:47-07:00
signature : default.sig
created : 2023-05-12T09:10:13Z
identifiers :
- name : 'pronom'
details : 'DROID_SignatureFile_V112.xml; container-signature-20230510.xml'
---
filename : 'REC00001.VOC'
filesize : 47231
modified : 2015-01-09T20:51:10-07:00
errors :
matches :
- ns : 'pronom'
id : 'UNKNOWN'
format :
version :
mime :
class :
basis :
warning : 'no match; possibilities based on extension are fmt/1736'
The RCA VOC file format seems to be undocumented, there isn’t much available. You can always download a copy of the RCA Digital Voice Manager software, which may or may not run on your current system, and convert the VOC files to WAV or you can use a piece of software coded in 2008 called “devoc“. The developer used to have an online website you could upload the VOC to and it would convert it automatically, but is not longer available. The code can also be found here.
Let’s take a look at the header of a couple of the files I have:
Most of samples I have show “VCP162_VOC_File” in the header, but I have one sample with “RP5120_VOC_File“. I have heard of others, one being “V432_Voice_File“. There could be more variations. One could assume the header is somehow associated with the model number of the device, but that doesn’t appear to be the case. Although there is a device with the model number “RP 5120“. It might be that the older RP series get one header and the newer VR Series get VCP? I will need more samples to confirm, if you have any send them my way. Also, according to the manuals, there is a SP and LP mode to manage the bitrate of the file to squeeze more minutes on the built in memory of these devices. This doesn’t appear to affect identification, but might be good to differentiate in the future.
For now you can take a look at the signature on my GitHub page.
All I had to go on was it was an Adobe format and the acronym “ACD”. One of the first results that came up in a google search was a post in the Adobe forums with someone asking what to do with some old ACD and ACI files they found on a disc, circa 2000, labeled “Adobe Capture”. The only thing I remember about Adobe Capture was some scanning tools related to Adobe Acrobat, but I didn’t remember coming across any ACD files related to Acrobat.
Initially it wasn’t easy to find more information on this format. Eventually I was able to narrow it down to stand-alone software adobe released called “Adobe Acrobat Capture”. Originally released in 1995 it was eventually discontinued in 2010. The software was marketed under the ePaper name and connected to Acrobat through the creation of a PDF from scanned images. The software was compatible with many scanner models and would process the scanned images, run Optical Character recognition, and export to a searchable PDF. These tools are built into Adobe Acrobat today.
One of the reasons the software was being so elusive is the fact it was sold with a high price tag and required the use of a hardware key, or dongle, in order to process scans. The hardware key also managed the type of license you purchased which may limit the number of pages you are allowed to scan within a certain period of time. So the software is very difficult to run today, if you do happen to find a copy out there in Internet land.
In order to document these file formats for preservation purposes I needed to find some samples. I was excited to find a demonstration CD on the Internet Archive, but unfortunately it contained no examples of the ACD file format.
A little sleuthing on the Wayback Machine helped me find a few user guides and brochures. I was also able to find there was three versions of Adobe Acrobat Capture. In a Product Brochure, you can see a screenshot of the software with a document open with the ACD extension.
If you are OCD like me you might have noticed the window in this screenshot is typical of the older Windows 3.1 or Windows NT system. So this was indeed an older product released by Adobe.
The Adobe Acrobat Capture 3.0 Demonstration CD-ROM from the Internet Archive luckily has a UserGuide PDF on the disc and was able to help me understand the ACD format a little more.
Looks like the ACD format is an intermediate format used by the software to manage the process between scanning and export to PDF. ACD was also defined as an “Acrobat Capture Document” which makes sense. They were also mentioned as being “multipage files in Acrobat Capture Document (ACD)”. The UserGuide also mentioned an ACP format which it referenced as “one-page files are in Acrobat Capture Page (ACP) format.” So more research is needed.
Lets start with Adobe Acrobat Capture 2.0 as I managed to get a few samples from an installer I found. Here is a hexdump of an ACD file and its corresponding ACI file.
The ACD file is unique, PRONOM and even TrID was unaware of the format. But to the keen observer, the ACI format is very recognizable. You may have seen this header before:
Lets take a closer look at an ACI file to see if they are a true TIFF image or if there is any customization to the format.
Looks like a true TIFF image with no special tags or unique properties. They are 1-bit TIFF’s compressed with CCITT RLE. Not sure there would be any need to create a special signature for these ACI files.
Looking closer at the ACD file format, we can see they reference ACI files, so probably safe to assume the ACD file doesn’t contain the full raster data for each image:
From the limited sample set I have access, all the ACD files begin with the same Hex values, “02044747C900”. Along with the common header we can assume there should be at least one ACI file referenced in the first part of the file. Because it is referenced as a filepath, the ACI string would be variable in its offset.
Adobe Acrobat Capture 3.0 turns out to be a different format. But looks familiar………
The ACD has some of the same hex values as the previous version, but with some extra bytes at the beginning and it looks like the ACP is a straight up PDF. But may have some interesting tags, like “CAPT_info”.
The problem we will face when trying to write a signature for this version of ACD is the container signature needs a static file name to reference, and it appears the name of the container is also the name of the ACD file within the container. So every file will be different. I wish there was a way in the PRONOM signature syntax to reference an extension and ignore the filename, but currently there no method to do this. The only thing inside the container which seems to be consistent is the file “FILES.LST”. So lets take a peek inside if it.
hexdump -C FILES.LST | head
00000000 5b 41 43 44 31 5d 0d 0a 49 53 43 4f 4d 50 4f 53 |[ACD1]..ISCOMPOS|
00000010 49 54 45 3d 54 52 55 45 0d 0a 4e 55 4d 46 49 4c |ITE=TRUE..NUMFIL|
00000020 45 53 3d 31 0d 0a 46 49 4c 45 4e 41 4d 45 31 3d |ES=1..FILENAME1=|
00000030 43 6f 6e 74 72 61 63 74 2e 61 63 70 0d 0a |Contract.acp..|
Ok, there seems to be some static information that is unique to the ACD format. I bet the string “[ACD1]” would be sufficient enough to make a solid signature.
This is a good format example of a limited amount of information on the file format used by a well known company which has become obsolete and disappeared. Take a look at my signatures, maybe you have some old ACD files you were unaware of!
I have to admit, often when I am researching file formats I can get distracted by a shinier format I come across. I often go down rabbit holes and forget the reason I started down the path I am on. I try and focus on the current needs in my life as a Digital Preservation Manager, but can get easily sidetracked. I always look forward to November every year so I can celebrate World Digital Preservation Day which sometimes comes along with a PRONOM research week. This gives me a chance to look at formats that may need attention which are not normally on my radar.
This week I a taking a look again at Multiplan. There is a PRONOM PUID for version 4, but does not have a description nor does it have a binary signature. It is was also lacking a File Format Wiki entry. So I decided to dive in. I had already bumped into the format while doing some research on early Microsoft Excel formats. This includes the SYLK format which needed a little update.
Microsoft Multiplan was the parent of Microsoft Excel. Multiplan was built for many different types of computers in the 1980’s, but was never ported to Windows. So to use Multiplan you have to be comfortable with using DOS. If you want to take Multiplan for a spin, head over to PCjs Machines and load up one of the many emulated systems they have.
In the end, Multiplan had four versions, but the last one, version 4.2, had some big changes, especially to the file format. More on that in a minute.
The DOS files for Version 2 begin with 0CEC0000 08AB0800, but a file for the Xenix system starts with 0AEC0000 08AB0800. So it appears the first byte may be different depending on the system.
The DOS files for Version 3 begin with a similar hex pattern, 0CED0000 08AB0800. This would make sense as the documentation for Multiplan 4.2 states it supports opening of Version 2 & 3, but not Version 1.
There was also a companion product that went along with Multiplan, it was called Microsoft Chart. Here is a file from version 3:
The Chart file format has a similar byte pattern with the 08AB pattern and looks similar to the BIFF format. We will have to make sure it doesn’t conflict with any signatures so it can be identified separately.
Version 4 of Multiplan was the first to use the BIFF (Binary Interchange File Format). Technically Version BIFF2, not much is know about BIFF1 or if it ever existed. BIFF2 is the exact same format as Excel 2.0 used, so there will be some problems if we want to identify them separately. They currently identify as fmt/55.
You can see in the hex values above a difference of two bytes in the header. The reason the Multiplan file identifies as an Excel 2 file is the PRONOM signature ignores those two bytes and allows them to be anything. Some specifications say these aren’t used, but clearly there is a use for them. We could probably use the same signature for Multiplan, but include the two bytes, then set the priority to the Multiplan signature.
The hex values for the first 4 bytes have a similar pattern. 0CEF, Which seems to be in sequence where Version 3 left off. Microsoft calls this new format, New or Normal Binary File Format. They claim it is “the fastest loading and fastest saving file format ever“! Exciting as the new format probably was, it didn’t last long. Multiplan was phased out so Excel could shine.
When I was younger I didn’t use DOS very often because the computer my father brought home in the mid 1980’s was a Macintosh. I use DOS more now in my research then I did when I was younger. Using the DOS interface is not easy. There are a lot of key commands you need to know intuitively just to navigate, but it is fascinating to see how far software has come. Early Excel, Multiplan, and Chart were all intertwined, but hopefully combing through all of these samples can bring some clarity. Take a look at the draft signature I made and all the samples that go with it on my GitHub page.
There really is no “Macintosh Format”, but there sure are a lot of formats you only find on the MacOS. From Resource Forks and iWork formats to unique sound formats, MacOS has them all! Majority of cross-platform software vendors have done a much better job in recent years in making their file formats the same across platforms, but for Apple, they love to make things unique, just for their platform.
Take EMLX for example. Seems to be a trend to add “X” to the end of an older format to breath new life into it. The EML format, or Electronic Mail, has existed for a few decades now, but in 2005 Apple updated their Apple Mail application to use a new format, EMLX.
As far as I know, Apple hasn’t released any documentation on the EMLX format, but many folks out there have asked the question and have been able to “reverse engineer” the format. Lets take a look.
An EMLX file consists of three parts:
bytecount on first line;
email content in MIME format (headers, body, attachments);
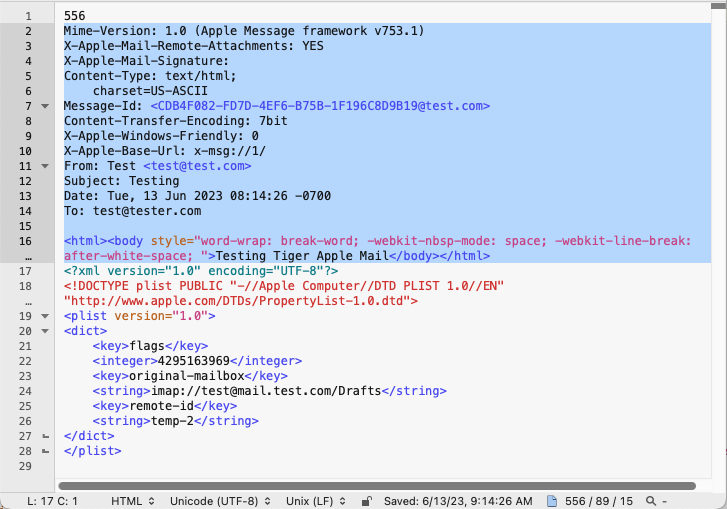
The bytecount is a variable number which consists of the total bytes starting from the start of the MIME format, including HTML, to the start of the XML property list. Lets look at a simple EMLX.
The byte count is on line 1 with the MIME email (EML) taking up the 556 bytes, then the XML plist at the end. You may ask, what is a plist? Well, it is another Apple (originally NextStep) invention which is embedded throughout the MacOS operating system. A Plist is usually an XML with keys but can also be in a binary format. The Plist can contain properties of the email within Apple Mail like special color flags, tagged as junk, date received and last reviewed.
If you do happen across an EMLX file or group of them, there are a few tools you can use to convert them to a plain old EML. There are python libraries or many other tools to do the job.
But first we need to be sure of identification beyond the extension. Adding this file format to PRONOM would help in identification for preservation purposes. If ran through PRONOM today we get:
filename : '9.emlx'
filesize : 18582
modified : 2023-10-26T22:16:25-06:00
errors :
matches :
- ns : 'pronom'
id : 'fmt/950'
format : 'MIME Email'
version : '1.0'
mime : 'message/rfc822'
class : 'Text (Structured)'
basis : 'byte match at [[31 17] [599 4] [339 6] [426 6] [90 14]]'
warning : 'extension mismatch'
Because the format has a EML plain text format within its structure, it is assumed to be an EML file. While technically accurate, Identifying as a unique EMLX format would be beneficial in a preservation system so you can properly assign risk and choose the right tool to parse or migrate.
In looking at the three parts of an EMLX format, we know the EML file is not a good way to show the difference as they are the same structure. The byte count on the first line is variable, so there is no static byte sequence to use for identification. That leaves the Plist section at the end to distinguish the difference.
The PRONOM entry for a Plist looks for the typical XML strings present in most XML files, but then uses the root element “<plist version=”1.0″>” for identification. We could combine the existing EML signature and the Plist signature to identify an EMLX, or just take the existing EML signature and put in a small byte sequence for the closing of the </plist> tag near the EOF? There would be a need for a priority over EML, both would essentially accomplish the same thing.
Take a look at latter idea on my GitHub page and tell me which makes the most sense.
If digital preservation had an extension it most likely would be .DP
Unfortunately, it’s taken. Say hello to Digital Paper.
In the early 1990’s, folks started to share documents with each other through the their phone lines. The early internet, BBS, AOL, CompuServe and the like allowed people to share ideas through applications like Word/WordPerfect Documents. Most people had a copy of the popular software and that software could open documents from their competitors, but fonts were always a problem. Technically a font is software as well and needs a license to be used. Also printers at the time dictated what the document might look like when opened, so your document may look different on someone else’s computer. This lead to a few innovations in the software market Digital Paper.
The idea is simple, create a format which could be opened with a free viewer which includes all the parts to make it look and print just like it was intended to. You may have already guessed who the winner in this space tuned out to be, yes, the PDF format. You can’t tell the history of the PDF Format without mentioning others that tried their luck to be the leader in portable document formats . WordPerfect’s Envoy format was one, Common Ground Digital Paper was another.
No Hands Software which started in 1990, developed the idea of making your documents truly portable. They released the Common Ground Maker and Viewer software in 1993. By 1996 the company was doing so well they were bought for $6 million by Hummingbird Ltd. PDF soon became so ubiquitous, formats like Common Ground and Envoy fizzled out. That doesn’t mean they didn’t have a big impact and still can be found in quite a few places.
Apple was one of the bigger users for awhile, but the format can still be found floating around today.
The Common Ground Digital Paper has some similarities to the PDF format, but the biggest different is the format is proprietary and not open like PDF. Another difference is you could embed the viewer into the file, this would make an executable on both Windows and Macintosh. Very convenient for sending to those who may not have the viewer or can’t install the viewer on their system.
Common Ground had two different viewers, a pro viewer with more features and a Mini Viewer with basic features and which was free to download and distribute from their website. Unfortunately, they linked to an FTP site which no longer is available and so finding the viewers today can be difficult.
I came across a boxed version 1 for Macintosh of the software a few years back, but have yet to find other full versions. The software did change hands a bit, but seems to have topped out at Version 4 in the late 1990’s. Let’s take a look at the file format for the samples we do have.
Version 1 for the Macintosh was the first I believe, coming to Windows shortly afterwards. The format was even assigned a MimeType for use on the web and the application gives us a little insight into the format.
The commonground file format does have versions (two at the moment). They *are* internally documented with a file signature, allowing commonground viewers to automatically handle both old and new format files. Therefore, I don’t believe a ‘version’ parameter is needed.
A Content-Type of “application/commonground” indicates a document in the Common Ground portable file format, also known as Digital Paper.
Encoding considerations: Common Ground files are in a binary format. Some encoding will be necessary for MIME mailers as in application/octet-stream. Common Ground files for the Macintosh are encoded in the data fork of a Macintosh file. The file type is APPL, the creator is CGVM.
If we look at a sample from Version 1 for the Macintosh we find the follow hex values:
In all the samples I have the first 8 bytes are not consistent, but the next four bytes are. CGDC, which happens to be the registered type on the Macintosh. Convenient. But it appears later versions are not the same.
These files are from a later version and have a different string at byte 8. DPL2 & DPL3. In the MiniViewer you can request document information and it provides some basic metadata for each file.
I only have one example of the DPL3, but a couple examples of DPL2, and it seems like DPL2 comes from a Version 3 DP Maker and DPL3 comes from Version 4 Maker. Need to see if I can find a Version 2 file and see if it follows the same pattern.
This file format is not currently in PRONOM. From what I have gathered I could add three signatures. There could be some other variations out there and the password protection needs to be considered. Maybe I’ll take Nick Gault’s offer and request the format which was available starting in the middle of 1995. Think they’ll deliver?
I had access to my first Macintosh computer around 1987. My father brought it home and I spent hours on it playing games and occasionally writing reports for school. The Macintosh Plus computer had one floppy drive and no hard drive. I remember playing the game Orbiter which had two floppy disks and right in the middle of game play it would pause and ask me to insert disk 2, then quickly ask for disk 1 again. The struggle was real. I spent years using many different Macintosh computers and now own more than I wish to admit. I’m preserving them!
The wild world of digital preservation has been a little lacking on the Macintosh side of things as I have come to realize. There still not a great way to manage Resource Forks in many preservation systems and the identification tools are mainly focused on the data bytetreams and not any system specific attributes Macintosh used often.
The PRONOM registry has either referenced early Macintosh specific formats or missed them entirely so I have been slowly working on a few to close that gap.
Interestingly enough, many Microsoft programs initially made their GUI debuts on the early Macintosh before making their way to Windows. Excel is one I am working on, as Version 1 is not identifiable in PRONOM, it was Macintosh only at the time.
Another is PowerPoint, I recently submitted two new signatures to PRONOM.
fmt/1747: Microsoft PowerPoint Presentation v2.x. Full entry added.
fmt/1748: Microsoft PowerPoint Presentation v3.x. Full entry added.
fmt/1866: Microsoft Powerpoint for Macintosh v.2. Full entry added.
fmt/1867: Microsoft Powerpoint for Macintosh v.3. Full entry added.
PowerPoint was initially released in 1987 on the Macintosh platform. It was developed by a company called ForeThought. Version 1.0 on the Macintosh was under this name, until it was bought by Microsoft only three months after being released. The history of PowerPoint can be discovered at Robert Gaskins, one of the original developers, website and book he wrote. The available information provided by Microsoft is only for the OLE format, covering versions 4.0 until 2003.
So, lets take a look at the Powerpoint original file format, before OLE.
Type/Creator RF DF Date Filename
f SLDS/PPNT 0 932 Oct 10 19:10 PowerPoint-v1
Luckily the early PowerPoint files did not have a Resource Fork. The Data Fork, if you haven’t noticed, has an interesting set of hex values at the beginning of the file. 0BADDEED is the first 4 bytes. If we look at a PowerPoint version 2 file from Windows.
The file format is the same, but because of the weird world of endianness, the first few bytes are in reverse order, EDDEAD0B.
Obviously we need to discuss this magic number and the meaning behind “Bad Deed”. This question was asked previously by the digital preservation community. I have a previous blog post about the use of words for the magic number CAFEBEEF as it was used with with JAVA class files and Express Publisher in the 1990’s. BADDEED looks like another clever use of the hex values that formed words. But was there a story behind the words? Joe Carrano asked if this string might be hexspeak. I wanted to know more so I asked some one who might know.
Robert Gaskins was kind enough to chat with me for a bit about the early days of PowerPoint.
I had a theory on the possible meaning behind BADDEED, so I asked him what the feeling was like between Apple and Microsoft at the time. I had heard for years that PowerPoint was originally created for the Macintosh, but Robert informed me:
In fact, PowerPoint was designed first for Microsoft Windows,
and its first spec shows that: “All the screen shots, menus, and
dialogs were set up to look like Microsoft Windows, not like
Macintosh.” (Gaskins, Sweating Bullets, p. 92) You can see that
Of course, we turned out to have been right all along. PowerPoint on
Mac was much loved, but sales remained poor because Mac sales were
so poor. It was only after we shipped on Windows that PowerPoint gained
the dominant market share which has characterized it ever since, and
Windows PPT outsold Mac PPT very quickly. (Gaskins, Sweating Bullets, p. 403)
So my original thought was that there was some bad feelings around this Apple, Microsoft battle which has been the sentiment for quite some time. So when I asked if any of that influenced the use of BADDEED, I was told:
So, far from being disgruntled by expanding PowerPoint to Windows,
that had been our goal all along, and its achievement was the most
important success we had.
I judge that you are fully aware of all that, and that
your question is more, “was there any bad deed signified
by the Mac hex value chosen?” No, it was just the poverty
of choice when you only have six letters.
So there you have it. The use of the hex values 0x0BADDEED, was simply chosen from a limited set of values when looking at words hexadecimal could spell. I guess I should never let the truth get in the way of a good story.
I continued to have a wonderful conversation with Robert and also asked him for some details on the rest of the PowerPoint file format. I was hoping there might be some documentation out there explaining the early format before Microsoft took over. Robert said:
I don’t know of any such documentation apart from the official
Microsoft support files available online. I don’t have any such
information. I know that Dennis Austin deposited some of our
working files at the Computer History Museum (not online):
and it’s likely that some information is there–if nothing
else, it claims to contain a source code listing for PPT 1.0
which would contain the code to read the file format.
So there might be some information in at the Computer History Museum worth looking into.
As far as I could tell from the available online information, there is a few differences between Version 1.0 and Version 2.0, the biggest being the fact that 1.0 did not have an option to print in color, amount a few other minor things. Here is a screenshot of a page from the Microsoft PowerPoint 2.0 documentation on archive.org.
I suppose with the signature additions of the Macintosh and Windows versions 2.0 and 3.0 of the PowerPoint file format in PRONOM, that should cover most needs. Currently my PowerPoint 1.0 files identify at 2.0 files, so I may need to have them adjust the PUID to include both versions 1.0 and 2.0 as they are so similar. If I am able to find a difference or get my hands on the original source code I may find a better solution.
Working with files in todays world is much different than before. Today getting files back and forth from the cloud or through email is relatively easy, unlike the early days when we used FTP sites and needed to encode our data to properly transfer. I remember using an FTP program on my old Mac called Fetch. We had to determine if the content was to be transferred as text or binary.
Picking the right encoding was critical to getting the content transferred correctly, this was even more critical when working with Macintosh files which needed a resource fork and/or finder attributes to work properly. In those cases a MacBinary or BinHex file was required! Fetch would automatically identify those formats and decode them for you.
If you need a refresher on MacBinary and AppleSingle, you can view my iPres 2022 presentation.
One format I didn’t spend much if any time on is the BinHex format. BinHex was a format born out of necessity to move files back and forth across the World Web Web, bulletin boards, AOL, Compuserve, and the like. The FTP program Fetch glossary describes BinHex as:
BinHex (sometimes called BinHex4) is a format for representing a Macintosh file in text form.
The Macintosh file is converted to a series of lines, each made up of letters, numbers, and
punctuation. Because BinHex files are simply text, they can be sent through most electronic mail
systems and stored on most computers. However the conversion to text makes the file larger, so it
takes longer to transmit a file in BinHex format than if the file was represented some other way.
The suffix “.hqx” usually indicates a BinHex format file.
You can still find many of these HQX files floating around the interwebs and on older CDs from the 1990’s. One such CD recently came into my possession. I managed to get a copy of the book “Internet File Formats“, by Tim Kientzie. It came with a CD-ROM with lots of goodies included. Some sample files, specifications, and software. The disc itself is an ISO 9660 partitioned disc, but includes a few Macintosh formats, so the author put many of the software files in the HQX format to maintain the much needed resource fork Macintosh applications need in order to run.
I initially ran the whole disc through DROID to get an idea what was on the disc and if any sample formats were unidentified (something I do regularly), and found majority of the HQX files didn’t identify as they should have to PRONOM PUID x-fmt/416. The signature is an older one, from 2010, but since the format isn’t updated anymore it should be solid. Or so I thought.
Since BINHEX files are encoded as text, lets take a look at a couple of these from the disc which didn’t identify.
The PRONOM signature currently is:
File extension: hqx
Name BinHex Binary Text
Description Header: (This file must be converted with BinHex
Byte sequences
Position type Absolute from BOF
Offset 0
Value 28546869732066696C65206D75737420626520636F6E76657274656420776974682042696E486578
That “Value” listed in hexadecimal decodes to: “(This file must be converted with BinHex” as listed in the description. We can see this line in the file above, but the signature assumes the value begins at offset 0 from the beginning of the file. So its looking for that value at the start of the file, but this file seems to have some additional text before the value. What does the specs say?
The whole file is considered as a stream of bits. This stream will
be divided in blocks of 6 bits and then converted to one of 64
characters contained in a table. The characters in this table have
been chosen for maximum noise protection. The format will start
with a ":" (first character on a line) and end with a ":".
There will be a maximum of 64 characters on a line. It must be
preceded, by this comment, starting in column 1 (it does not start
in column 1 in this document):
(This file must be converted with BinHex 4.0)
Any text before this comment is to be ignored.
The characters used is:
!"#$%&'()*+,- 012345689@ABCDEFGHIJKLMNPQRSTUVXYZ[`abcdefhijklmpqr
Ok, so in the specs we can see the “Value” string must be there, but according to the specification, any text before this comment is to be ignored. So adding some instructions and even an email header at the beginning is ok, as long as the value string is there right before the encoded data.
We also learn a couple interesting things. The first character of the first line after the string should be a “:” and the last line should end with a “:” as well. That could help make the signature more solid. We also learn there are a maximum of 64 characters per line. The last line will probably not have full maximum, but the previous lines should…. I wonder if we could use this fixed position from the initial “:” to add even more strength to the signature.
Adding the 4,084 bytes at the beginning allow for additional text. This value worked for my samples but there could be others out there with more. The {6-9} bytes in between the string and the colon account for the various way newlines are encoded. Sometimes is one “0A” byte, other times it is “OD”, and others its both. After testing, adding values in the signature to account for the 64 byte line can fail if the file has only one line, so I left it out.
The EOF should just be the colon (3A), but I found many of my samples had various line endings and other random characters. Hence the 64 bytes for max offset.
Also, the current PRONOM entry doesn’t include the Mime-Type, which is: “application/mac-binhex40”
Hopefully this update will add some strength to the signature and follow the specification closer. The new signature even works on files with extra content at the beginning!
There are a number of software titles you can use to encode and decode a BinHex file. On a modern Mac, try using The Unarchiver, or Stuffit Expander. From the commandline, you can use the macutil library or the CLI version of Unarchiver. Although the MacOS has a built in utility to decode BinHex files. If you are using a classic version of Macintosh OS, you can find a number of utilities on Macintosh Garden.
Oh, and also, the CD-ROM I mentioned earlier has a few “fun” features. Not sure if they are on purpose or if errors were made during mastering, but a few filenames have some hidden extra characters and one folder puts any tool traversing the directory into a loop, even droid. Have fun!
This week I am at the annual iPres digital preservation conference. It is an amazing week of meeting colleagues and old friends who share the same passion of digital preservation. Outside of this community and my co-workers, talking about file formats and digital preservation usually bores people to death and I can hear some of them mumble under their breath, “nerd”! I term I am happy to accept.
At the conference, which is in lovely Urbana-Champaign Illinois this year, I am trying to soak in all the amazing talks and conversations about the challenges facing our work. There were a couple great workshops on Persistent Identifiers and Digital Object Storage Criteria. The presentations I made were of course on File Formats, documentation, and obsolescence. One talk before my panel conversation was about the ubiquitous Adobe Flash format.
The paper, “Around for Decades, Gone in a Flash: How we dealt with Flash objects and the National Archives of the Netherlands” was presented by Lotte Wijsman and Marin Rappard. They knew they had flash objects in their web archives and wanted to go through the process of how they might be preserved and accessed. They started out looking for any files with “FLA”, “SWF”, and “FLV” as extensions. This proved problematic as there were references to those extensions within other documents and objects. They then used DROID to identify the flash formats. “SWF” has quite a number of format PUID’s.
PUID
Format Name
Format Version
Extension
fmt/104
Macromedia Flash
1
swf,
fmt/105
Macromedia Flash
2
swf,
fmt/106
Macromedia Flash
3
swf,
fmt/107
Macromedia Flash
4
swf,
fmt/108
Macromedia Flash
5
swf,
fmt/109
Macromedia Flash
6
swf,
fmt/110
Macromedia Flash
7
swf,
fmt/505
Adobe Flash
8
swf,
fmt/506
Adobe Flash
9
swf,
fmt/507
Adobe Flash
10
swf,
fmt/757
Adobe Flash
11
swf,
fmt/758
Adobe Flash
12
swf,
fmt/759
Adobe Flash
13
swf,
fmt/760
Adobe Flash
14
swf,
fmt/761
Adobe Flash
15
swf,
fmt/762
Adobe Flash
16
swf,
fmt/763
Adobe Flash
17
swf,
fmt/764
Adobe Flash
18
swf,
fmt/765
Adobe Flash
19
swf,
fmt/766
Adobe Flash
20
swf,
fmt/767
Adobe Flash
21
swf,
fmt/768
Adobe Flash
22
swf,
fmt/769
Adobe Flash
23
swf,
fmt/770
Adobe Flash
24
swf,
fmt/771
Adobe Flash
25
swf,
fmt/772
Adobe Flash
26
swf,
fmt/773
Adobe Flash
27
swf,
fmt/774
Adobe Flash
28
swf,
fmt/775
Adobe Flash
29
swf,
fmt/776
Adobe Flash
30
swf,
Even the Macromedia/Adobe Flash Video format has a PRONOM PUID, x-fmt/382.
The format missing from PRONOM is the FLA format. FLA is the native format for Macromedia/Adobe Flash for saving the source project of your Flash document. SWF files are compiled from the FLA source. This means the the SWF will be the most common format found on the web and in public places, but the FLA format might be more often found on local drives and working folders.
The Flash format and software was actually created by Future Wave software in 1996 as FutureSplash Animator, but was shortly bought by Macromedia later that year and Flash 1.0 was born. FutureSplash used the extension .SPA, but Macromedia changed it to FLA.
The format was initially based on the Microsoft Compound File Format or the OLE container format.
The move to a ZIP container included a new format, XFL. This XFL file is a simple text file with the text “PROXY-CS5″. In the DOMDocument.xml file we find an XML namespace, xmlns=”http://ns.adobe.com/xfl/2008/” and a version of the XFL structure, xflVersion=”2.1″.
This ZIP compressed FLA file is still being used in the current Adobe Animate software, which no longer uses the flash technology and uses more modern web formats like HTML5 to display the animations.
I took each version and made a PRONOM signature, which you can find here with samples. These container signatures should cover all the major changes for the format, but there is a problem……..
Turns out majority of the samples I have from many versions of Adobe Flash after CS5 have a ZIP Header error. When using the new signatures in DROID, the samples with the header errors will fail in the DROID’s zip library processing. The DROID logs shows this issue:
Could not process the potential container format (ZIP): file:///Flash5.5-S01v5.fla
Expected 25 more entries in the Central Directory!
The Central Directory header in a ZIP file is quite important to the proper function of the ZIP container. Wikipedia has a great explanation of the header. You may notice in the listing above the file “mimetype” is shown twice which is probably the extra entries the parser wasn’t expecting.
So currently the identification of majority of these FLA formats is on hold until a way is discovered to ignore the error and continue the container identification in DROID.
Before the days of streaming and devices likeSmart TVs, AppleTV and Fire sticks, a few companies tried their best to come up with ways to make viewing your media on your TV mainstream. In a previous blog post I touched on the Kodak PhotoCD method, but there is one you are probably even less familiar with. HighMAT. HighMAT, or High-Performance Media Access Technology was a technology co-developed by Microsoft and Panasonic. You may have at one point owned a DVD player which had the technology built-in, but may have never used it. It came on the scene around 2002, but was abandoned by 2008.
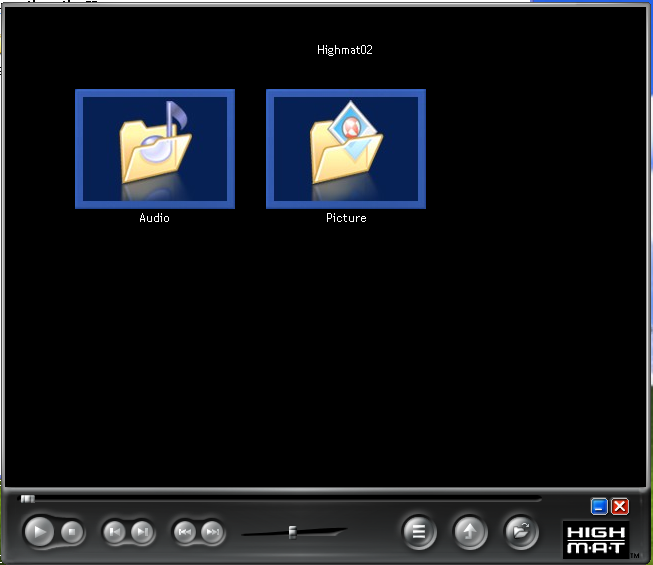
Panasonic DVD/CD Player with HighMAT playback.
There were quite a few devices stamped with the HighMAT logo. The technology allow you to playback any Audio and Images like a DVD, with a menu and everything.
There was three different types of HighMAT compatible devices, Audio, Audio-Image, and Audio-Image-Video.
Writing data to the HighMAT format could be done with a plugin for Windows which added the functionality to Windows Media Player for burning audio playlists to the HighMAT format or through the standard CD Writing Wizard built-in to Windows XP. An extra screen would come up asking if you would like to make the CD HighMAT compatible. Making video compatible HighMAT CDs could be done through Movie Maker.
When a HighMAT CD-R/CD-RW is authored we get an interesting CD. It appears to be a Mode 2 Form 1 format:
/dev/disk10 (internal, physical):
#: TYPE NAME SIZE IDENTIFIER
0: CD_partition_scheme *846.4 MB disk10
1: CD_ROM_Mode_2_Form_1 Highmat02 2.7 MB disk10s0
If you would like to check out a sample disc, you can grab the ISO or BIN/CUE here.
There is a lot going on here, lets take a look at a few of the formats we find in this disc structure. The files added to the CD are converted to WMA if you checked the “Convert Files” feature and are accessible like a normal data CD. The HighMAT folder is created to make a compatible HighMAT disc. Except for one XML file the rest of the files in the HighMAT folder all have an HMT extension. The author.xml file contains the root element <HMT> with some filenames indicating some of the HMT files may be thumbnails. If we open one of the HMT thumbnail files in a hex editor we can see:
Just a plain old JPG header. Exiftool tells us it is small 160×120 pixel image, must be a thumbnail. But lets take a look at another HMT file.
Even though the Menu.hmt file has the same extension as the thumbnails, this file is definitely not a JPG file with pixel data. Same goes for the Contents and Text files as well, unique formats.
The files in the playlist folder also have a unique format.
So it seems all the HighMAT folder really does is add compatibility for hardware to provide a menu to access the original data, providing playlists and thumbnails to navigate the data on your TV screen.
I came across one of these discs while processing a collection of CD-R discs donated to our library. Normally I would copy the images and other data off the disc to our preservation system, but this disc made me stop to think about the best way to preserve the data. Is a disc image appropriate or is the HighMAT folder even worth preserving if we have the original files from the disc? Finding hardware or a software player to present the disc as intended is getting harder to do. I am curious what others think of the value of this content.
I chose not to submit any signatures to PRONOM for the moment as we assess. It would be difficult to properly identify each format with all of them having the same extension, especially the JPG thumbnails as HMT is not a valid extension for the format. Take a look at my sample files and if you have come across this format before, let me know.
Let’s talk about Apple’s iWork software. Apple’s Office Suite of applications was first released in 2005 and provided a WordProcessor (Pages), Presentations (Keynote), and a little later, Spreadsheet (Numbers). They are exclusive to the Macintosh and iOS devices.
iWork was released in a few different versions. They get a little confusing as each application has its own version which all seemed to unify and stabilize in 2020. Here is a matrix of major versions.
Version
Package or ZIP
iWork ’05
Package
iWork ’06
Package
iWork ’08
Package
iWork ’09
ZIP
iWork 2013
Package
iWork 2014
ZIP
iWork 2019
ZIP
iWork 2020
ZIP
You may already be aware but MacOS can sometimes be weird. I use the term weird in a loving, sometimes proud way, but I admit, there was some “odd” choices made in regards to how applications and documents are used and stored files on a Mac.
On early Macintosh computers Apple used an interesting method of storing resources for applications and some file formats. The Resource Fork for an application contained all the “resources” needed to run in the operating system. It would contain all the icons, warning screens, graphics, sounds, etc. This held true until Mac OS X came along and then Apple started using a bundle or package format. Still in use today, what appears to be a single file or application is actually a folder of all the resources needed to run the application.
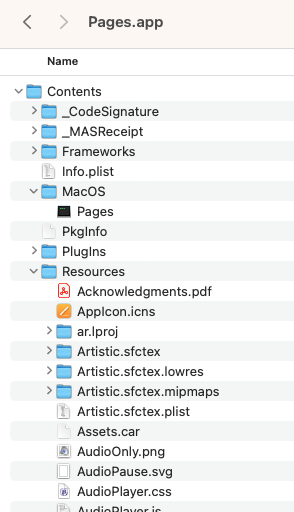
By right clicking or control clicking on the icon you can open the folder and see all the contents which make up the Application.
Nifty right? The MacOS which knows which extensions to treat as a package. If you were to move the application over to another system it would be a folder with the extension “.app”.
For an application I can see how this makes sense as it will only execute in the MacOS environment. The problem comes in when you use the same package method for the documents the application creates.
So instead of a single “file” with a bytestream, you get a folder of files which make up the file format. Here is Apple’s description:
Document Packages
If your document file formats are getting too complex to manage because of several disparate types of data, you might consider adopting a package format for your documents. Document packages give the illusion of a single document to users but provide you with flexibility in how you store the document data internally. Especially if you use several different types of standard data formats, such as JPEG, GIF, or XML, document packages make accessing and managing that data much easier.
Although bundles and packages are sometimes referred to interchangeably, they actually represent very distinct concepts:
A package is any directory that the Finder presents to the user as if it were a single file.
A bundle is a directory with a standardized hierarchical structure that holds executable code and the resources used by that code.
A couple years ago a processed digital collection made its way down to me. It had been processed by a new digital archivist and when I went to prepare the collection for preservation, I found a folder with the extension .pages and inside the folder a whole directory of files. Many of which they had renamed and arranged. Needless to say, I had to track down the original disk so I could properly preserve the file.
So looking back at the earlier table, iWork switched back and forth between the package format and a ZIP container. For preservation purposes, the ZIP container is easier to maintain outside the MacOS. Lets look a little closer at each. If you would like to follow along I have copied a few samples onto a hybrid ISO.
iWork ’05 through iWork ’08 used the same package format and structure. Because they are a package format, they are difficult to preserve as original files. I suppose you could zip them up, but probably the best option is to open with a current version of Pages and save to the newer ZIP container format.
iWork ’09 changed this practice. The documents saved from Pages, Keynote, and Numbers were contained in a ZIP file and can be identified using the PRONOM registry container signatures.
filename : 'iWork 2013/Pages2013-Sample09.pages'
filesize : 105900
modified : 2019-11-21T20:36:00-07:00
matches :
- ns : 'pronom'
id : 'fmt/1439'
format : 'Apple iWork Pages'
version : '09'
class : 'Word Processor'
basis : 'extension match pages; container name index.xml with byte match at 195, 76'
Then Apple went back to a Package format with iWork 2013. For reasons unknown. But the content and structure changed. Its a package format with a Index.zip instead of index.xml
Luckily Apple came to their senses and went back to the ZIP container format for iWork 2014 and later. The container signature looks for the IWA file Apple started using with iWork 2013.
filename : 'iWork 2014/Pages2014-Sample.pages'
filesize : 66256
modified : 2019-11-22T00:03:56-07:00
errors :
matches :
- ns : 'pronom'
id : 'fmt/1441'
format : 'Apple iWork Document'
version : '14'
class : 'Presentation, Spreadsheet, Word Processor'
basis : 'extension match pages; container name Index/Document.iwa with byte match at 16, 6; name Metadata/Properties.plist with name only'
Now iWork was not the only Apple software to use the Package/Bundle format for their documents. Be advised the following software may save to the package format.