If you remember the older post about Cafe Beef, you’ll appreciate the file format we explore in this post which uses using the Hex values “BE DEAD”. I guess they jinxed themselves because the software didn’t survive a refresh in 2009 and died. At one point the software was considered remarkable software being awarded 4.5 Mice by Macworld Magazine in August 2002.
When a colleague reach out to me recently with a file they were not familiar with I jumped in. I love a good challenge. The file had no extension, but was thought to have come from a Windows system. With a little digging I was able to identify the file as a Now Contact file which does have a Windows and Macintosh version, but with no extension, my money was on the file coming from the Mac.
I started my search with the obvious, the first few bytes. Since I only had one file, I wasn’t sure if this would be helpful, but looking at the bytes, I figured it was significant.
% hexdump -C "CONTACT FILE" | head
00000000 be de ad 01 00 00 00 03 00 1d 5f a9 00 7d d1 8e |.........._..}..|
00000010 00 00 0e d8 98 89 d7 4b 00 8f 31 fd 00 00 3b f0 |.......K..1...;.|
00000020 00 de 76 56 be de ad 00 e6 02 b4 af 63 64 62 68 |..vV........cdbh|
00000030 00 00 00 00 00 00 01 8e 90 8f 56 13 00 0d 09 b4 |..........V.....|
00000040 00 0d 0b e0 00 0d 0c 50 00 0d 0b e8 00 0d 0c 58 |.......P.......X|
00000050 00 00 00 00 ba f3 fa eb 00 00 27 12 00 00 00 00 |..........'.....|
00000060 e6 02 b4 76 00 00 00 00 00 00 00 00 00 00 00 00 |...v............|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
The first three bytes are “BE DE AD“, BE DEAD seems to be done on purpose. A quick search on the web showed no results, no mention of this unique header. I even turned to AI, asking grok if it know the source of this byte sequence. It had no idea. I began digging through the file looking for clues to its software source. The ASCII text I could see indicated some sort of customer database, that along with the file name of “CONTACT FILE” seemed to confirm. I found some dates from 2002 and started looking at popular CRM and PIM software at the time. I then found a reference to a note the user left saying they opened the file on a different Power Tower Pro. I owned one of these clones back in college, so I immediately knew they were using a Macintosh! A quick search of popular contact management software from the early 2000’s revealed a few suspects. I took a look at a product from Now Software, Now Up-to-Date & Contact version 3.9 and I found the header I was looking for! Had the file sent to me retained its extended attributes from the Mac, I would have found this software much quicker.
Now Software has been around since 1990 and was purchased at one point by PowerOn Software. Now Up-to-Date came around in 1992, but Now Contact wasn’t added until 1994. Version 1.0 of the software was standalone and was popular, but simple, when Now Software bundled it with the Now Up-to-Date software in 1995, they skipped version 2 to be in sync.
The Now Contact software has a few functionalities including a Word Processor, but lets stick to the contact manager for now. Let’s take a look at a sample file from version 1.
% hexdump -C "Sample Contact File" | head
00000000 00 00 4c 47 00 00 00 03 a8 ee f6 c6 a8 ef 9b 95 |..LG............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000100 12 bc 00 2b 73 74 61 74 00 00 00 01 00 00 00 04 |...+stat........|
00000110 00 00 00 fc 73 74 61 74 00 00 00 02 00 00 01 00 |....stat........|
00000120 00 00 06 44 4b 6e 44 42 00 00 00 00 00 00 07 44 |...DKnDB.......D|
00000130 00 00 04 68 4b 6e 44 42 00 00 00 01 00 00 0b ac |...hKnDB........|
00000140 00 00 06 12 4b 6e 44 42 00 00 00 02 00 00 13 ac |....KnDB........|
00000150 00 00 00 70 4b 6e 44 42 00 00 00 03 00 00 15 ac |...pKnDB........|
00000160 00 00 00 b6 4b 6e 44 42 00 00 00 05 00 00 16 64 |....KnDB.......d|
This file does not have the “BE DE AD” header, but something else. I do see a repeated pattern of the text “KnDB” which also happens to be the Type code used on the Macintosh.
% getfileinfo "Sample Contact File"
type: "KnDB"
creator: "NIC!"
attributes: avbstClinmedz
created: 10/23/1993 13:57:10
modified: 10/24/1993 11:18:58
Another sample
% hexdump -C NC1-s02 | head
00000000 00 00 36 20 00 00 00 03 e6 03 e7 1a e6 03 e7 41 |..6 ...........A|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00000100 0c dc 00 26 73 74 61 74 00 00 00 01 00 00 00 04 |...&stat........|
00000110 00 00 00 fc 73 74 61 74 00 00 00 02 00 00 01 00 |....stat........|
00000120 00 00 06 44 4b 6e 44 42 00 00 00 00 00 00 07 44 |...DKnDB.......D|
00000130 00 00 04 68 4b 6e 44 42 00 00 00 01 00 00 0b ac |...hKnDB........|
00000140 00 00 00 00 4b 6e 44 42 00 00 00 02 00 00 0b ac |....KnDB........|
00000150 00 00 00 20 4b 6e 44 42 00 00 00 03 00 00 0b cc |... KnDB........|
00000160 00 00 00 b6 4b 6e 44 42 00 00 00 05 00 00 0c 84 |....KnDB........|
These version 1 files don’t seem to have a static header, but they do have common bytes sequences. I will need to make more samples to get a proper signature constructed.
Now Contact skipped version 2 so the next version to be released was 3.0. What do these files look like?
% hexdump -C "Sample Contact File" | head
00000000 be de ad 01 00 00 00 03 00 00 a7 62 00 00 03 fc |...........b....|
00000010 00 00 00 19 00 01 6e 9a 00 00 36 94 00 00 00 55 |......n...6....U|
00000020 00 01 42 ea be de ad 00 b4 25 c0 65 00 01 63 6b |..B......%.e..ck|
00000030 00 00 00 87 00 00 00 6c fc 63 8e a8 6f 62 6a 65 |.......l.c..obje|
00000040 00 00 00 81 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 00 01 00 00 00 80 00 00 00 36 63 6d 6e 74 00 00 |.........6cmnt..|
00000060 00 80 00 00 00 00 00 00 00 00 00 00 00 00 00 03 |................|
00000070 63 64 61 74 00 00 00 04 b4 25 c0 65 63 74 68 74 |cdat.....%.ectht|
00000080 00 00 00 00 63 73 65 6c 00 00 00 04 00 00 00 00 |....csel........|
00000090 be de ad 00 b4 25 c0 a4 44 4c 54 7a 00 00 00 ed |.....%..DLTz....|
They have the same header as the file I received. Let’s try and open my file in Now Contact 3.9.
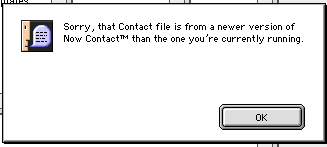
Oops, that didn’t work. There must be something in my file which tells the software it is from a newer version. After some digging in the file I can see some possible version text.
% hexdump -C "CONTACT FILE"
00000000 be de ad 01 00 00 00 03 00 1d 5f a9 00 7d d1 8e |.........._..}..|
00000010 00 00 0e d8 98 89 d7 4b 00 8f 31 fd 00 00 3b f0 |.......K..1...;.|
00000020 00 de 76 56 be de ad 00 e6 02 b4 af 63 64 62 68 |..vV........cdbh|
00000030 00 00 00 00 00 00 01 8e 90 8f 56 13 00 0d 09 b4 |..........V.....|
00000040 00 0d 0b e0 00 0d 0c 50 00 0d 0b e8 00 0d 0c 58 |.......P.......X|
00000050 00 00 00 00 ba f3 fa eb 00 00 27 12 00 00 00 00 |..........'.....|
00000060 e6 02 b4 76 00 00 00 00 00 00 00 00 00 00 00 00 |...v............|
00000070 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000003a0 00 50 00 21 00 f1 01 cf 00 00 00 82 00 00 00 34 |.P.!...........4|
000003b0 6b 65 79 73 00 00 00 82 00 00 00 00 00 00 00 00 |keys............|
000003c0 00 01 00 00 00 01 6b 65 79 68 00 00 00 15 76 34 |......keyh....v4|
000003d0 30 30 00 00 00 01 00 00 00 00 00 00 00 00 00 00 |00..............|
000003e0 00 00 00 00 be de ad 00 ba 42 cd 51 05 00 64 62 |.........B.Q..db|
000003f0 00 00 00 02 00 00 00 18 00 00 00 00 00 00 00 00 |................|
00000400 00 be de ad 00 b9 d0 15 aa 02 00 66 6c 00 00 00 |...........fl...|
00000410 14 00 00 00 2d b1 0b 27 34 76 34 30 30 00 00 00 |....-..'4v400...|
The file has some repeated text with v400. Sure enough opening the file in version 4 has no problems and I am able to view all the contacts and even allows me to export as a CSV. Looking at a sample file from a version 4 install confirms the version information.
% hexdump -C "Sample Contact File" | head
00000000 be de ad 01 00 00 00 03 00 07 5c 06 00 01 23 40 |..........\...#@|
00000010 00 00 00 10 00 17 9c 42 00 01 10 92 00 00 00 63 |.......B.......c|
00000020 00 10 37 3a be de ad 00 b7 39 82 7b 00 01 63 6b |..7:.....9.{..ck|
00000030 00 00 00 80 00 00 5d 62 52 66 a1 a9 6f 62 6a 65 |......]bRf..obje|
00000040 00 00 00 86 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000050 00 06 00 00 00 81 00 00 00 34 6b 65 79 73 00 00 |.........4keys..|
00000060 00 81 00 00 00 00 00 00 00 00 00 00 00 00 00 01 |................|
00000070 6b 65 79 68 00 00 00 15 76 34 30 30 00 00 00 01 |keyh....v400....|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000090 00 82 00 00 00 b4 6e 6f 74 65 00 00 00 82 00 00 |......note......|
Now Software updated the software for the a few years in the early 1990’s. There was Windows versions as well and the format is the same except one detail.
% hexdump -C NC452-Win-s01.NCT | tail
00004ff0 00 00 00 00 00 00 00 00 00 00 00 00 00 08 00 32 |...............2|
00005000 00 32 01 90 01 90 00 00 00 08 00 4f 00 32 02 01 |.2.........O.2..|
00005010 03 11 00 00 01 00 00 00 01 18 00 00 00 18 00 00 |................|
00005020 00 32 00 00 00 00 00 00 00 00 00 1c 00 32 00 00 |.2...........2..|
00005030 64 65 52 65 00 00 00 0a 00 01 ff ff 00 00 00 0c |deRe......??....|
00005040 00 00 00 00 00 00 4e fa 69 da 88 7b 00 00 50 54 |......N?i?.{..PT|
00005050 77 69 6e 73 |wins|
It appears in version 4, the final bytes would indicate “wins” or “macs”. This continued in version 5 which came out in 2005.
% hexdump -C NC501-s01.nct | head
00000000 be de ad 01 00 00 00 03 00 00 02 cf 00 00 1e 14 |?ޭ........?....|
00000010 00 00 00 11 00 00 5c 93 00 00 43 7e 00 00 00 50 |......\...C~...P|
00000020 00 00 59 da 00 00 00 34 00 00 00 2c 00 00 05 5e |..Y?...4...,...^|
00000030 00 00 02 cc be de ad 00 e6 02 e9 89 01 00 64 62 |...̾ޭ.?.?...db|
00000040 00 00 00 02 00 00 00 18 00 00 00 00 be de ad 00 |............?ޭ.|
00000050 e6 02 e9 91 63 64 62 68 00 00 00 00 00 00 01 8e |?.?.cdbh........|
00000060 be 63 10 4d 00 7f 63 c8 00 7f 65 64 00 7f 66 d0 |?c.M..c?..ed..f?|
00000070 00 7f 66 bc 00 00 00 00 00 01 00 00 e6 02 e9 8a |..f?........?.?.|
00000080 00 00 27 11 00 00 00 00 e6 02 e9 91 00 00 00 00 |..'.....?.?.....|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
00005ad0 00 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 |................|
00005ae0 01 00 00 00 00 00 00 00 00 1e 00 00 00 00 00 00 |................|
00005af0 00 00 00 1c 00 1e ff ff 00 00 00 00 00 00 00 00 |......??........|
00005b00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 08 |................|
00005b10 00 32 00 32 02 4f 03 11 00 00 59 da 57 7e a0 f3 |.2.2.O....Y?W~??|
00005b20 00 00 5b 28 6d 61 63 73 |..[(macs|
Also in the version 5 samples, we still see the v400 text, so it appears the format was not changed.
% hexdump -C /Volumes/File\ Formats/Now/NC531-s01.nct
00000000 be de ad 01 00 00 00 03 00 00 04 90 00 00 1e 14 |?ޭ.............|
00000010 00 00 00 11 00 00 54 83 00 00 43 7e 00 00 00 50 |......T...C~...P|
00000020 00 00 53 5e 00 00 00 34 00 00 00 2c 00 00 05 5e |..S^...4...,...^|
00000030 00 00 02 cc be de ad 00 e6 04 44 0e 01 00 64 62 |...̾ޭ.?.D...db|
00000040 00 00 00 02 00 00 00 18 00 00 00 00 be de ad 00 |............?ޭ.|
00000050 e6 04 44 5c 63 64 62 68 00 00 00 00 00 00 01 8e |?.D\cdbh........|
00000060 41 f7 ad 20 cc 8e b5 01 74 8f b5 01 e8 00 b6 02 |A?? ?.?.t.?.?.?.|
00000070 e4 00 b6 02 00 00 00 00 01 00 00 00 0e 44 04 e6 |?.?..........D.?|
00000080 11 27 00 00 00 00 00 00 5c 44 04 e6 00 00 00 00 |.'......\D.?....|
00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
*
000001e0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 be de |..............??|
000001f0 ad 00 e6 04 44 0e 02 00 66 6c 00 00 00 03 00 00 |?.?.D...fl......|
00000200 00 2d b1 0b 27 34 76 34 30 30 00 00 00 01 00 00 |.-?.'4v400......|
00000210 00 00 00 00 00 00 00 00 00 00 00 be de ad 00 e6 |...........?ޭ.?|
00000220 04 44 0e 02 00 66 6c 00 00 00 05 00 00 00 2d b1 |.D...fl.......-?|
00000230 0b 27 34 76 34 30 30 00 00 00 01 00 00 00 00 00 |.'4v400.........|
Now Up-to-Date & Contact released version 5.3 around 2008 which finally provided support for Intel processors. It was the last version released before Now Software attempted a full re-write of the software in 2009 named Now X (code-named “NightHawk”). The software did not receive good reviews and by 2010 the company ceased operations. So far I have come up empty in getting a copy of this doomed version, but I will update this post if I am able to get my hands on a copy.
For now, you can take a look at some sample files on Github, which I will also add some PRONOM signatures to soon.