Let’s talk about the DVD format for a minute. Specifically the miniDVD media format.

DVD’s are indeed versatile, as the name implies. You can find files on them written in many different filesystems, including digital video. DVD-Video is a video format which replaced VHS tapes as a main source of home movie entertainment. Eventually the public could afford to record their own video onto these discs and enjoy them for years. With the popularity of high definition video, DVD’s are not as popular as they once were, but still provide a decent experience.
I often see the DVD-Video format in archives I work with and we use tools to “RIP” the already digital data from the disc into a new format. I use the term “RIP”, to indicate we are not digitizing the format as it already contains digital data. DVD-Video is a standard that is used on most discs and looks something like this:
tree /Volumes/VIDEO_ESSENTIALS
/Volumes/VIDEO_ESSENTIALS
├── AUDIO_TS
└── VIDEO_TS
├── VIDEO_TS.BUP
├── VIDEO_TS.IFO
├── VIDEO_TS.VOB
├── VTS_01_0.BUP
├── VTS_01_0.IFO
├── VTS_01_0.VOB
├── VTS_01_1.VOB
├── VTS_01_2.VOB
├── VTS_01_3.VOB
├── VTS_01_4.VOB
├── VTS_02_0.BUP
├── VTS_02_0.IFO
├── VTS_02_0.VOB
└── VTS_02_1.VOB
3 directories, 14 files
There is usually a AUDIO_TS and a VIDEO_TS folder. The Video folder is full of video files, but the Audio folder is always empty. Apparently is was going to be used for an audio format that was abandoned, so it remains empty. Often times I will see this folder absent on non-commercial discs.
An issue that has come up many times is often I find folks copy the folder structure from the disc to preserve the video as they would with any digital file. This can be an issue as the structure was meant for software and hardware used to access the DVD-Video format. The files by themselves can often not provide the same experience, especially if the disc contains any sort of encryption, then the files are useless. This is a complex, multi-part format and should remain together in this structure or migrated to a new format, such as an MKV for preservation.
Enter the miniDVD. It is a smaller version of the standard CD/DVD optical disc size. It was very popular as a recording medium for some digital video camera’s. Much like the Sony miniDVD handycam I own. You can pop a blank disc into the camera and it prepares it for you, which takes a couple minutes, then gives you 20 minutes of recording in high quality and up to 60 minutes with a lower quality. The discs can hold up to 1.4GB and will have the same structure as its big brother.
tree /Volumes/2025_05_23_07H36M_PM
/Volumes/2025_05_23_07H36M_PM
└── VIDEO_TS
├── VIDEO_TS.BUP
├── VIDEO_TS.IFO
├── VIDEO_TS.VOB
├── VTS_01_0.BUP
├── VTS_01_0.IFO
└── VTS_01_1.VOB
2 directories, 6 files
It is missing the AUDIO_TS folder, which is fine, but here is the catch. In order for the disc to be readable by another device, it has to be finalized!
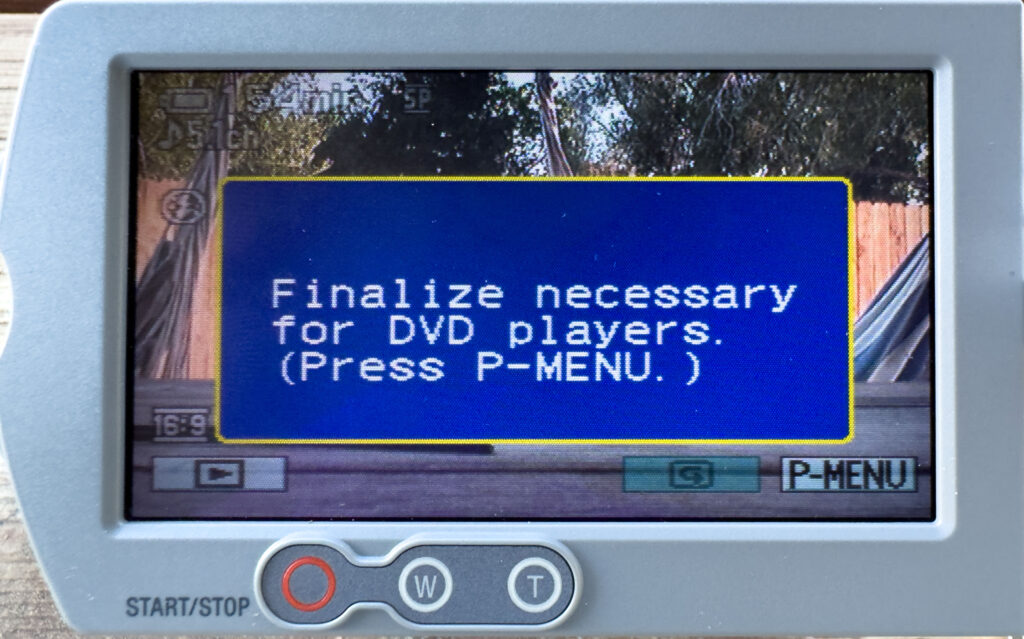
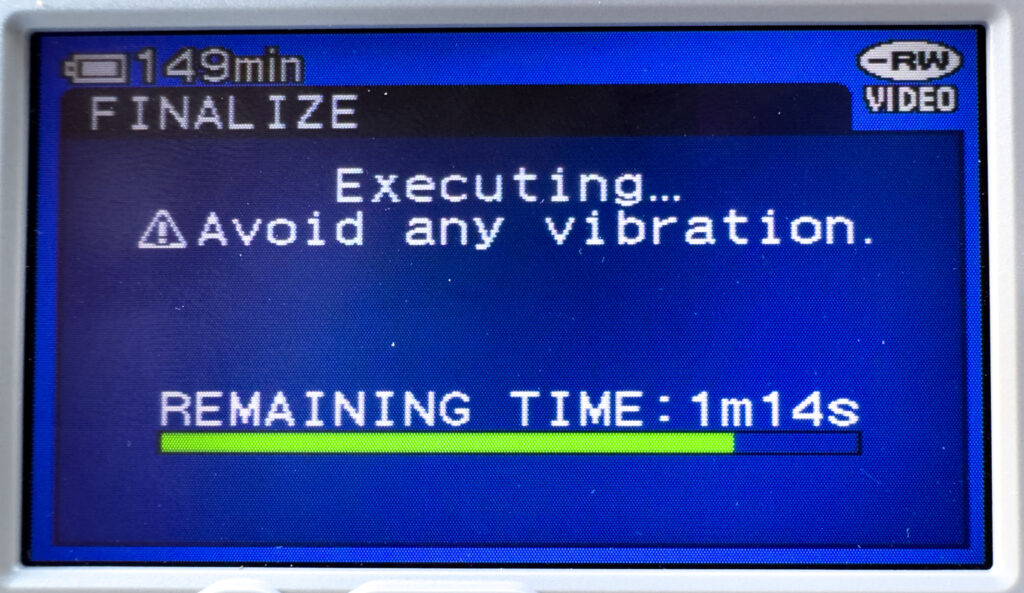
Finalizing is an action which has to happen to any optical disc to “close” out the disc. This process adds important directory and file system data so computers and DVD Players can read the disc properly. Many camera’s like mine and other DVD Recorders require this step when you are finished recording. Unfortunately, it’s an extra step which can take a few minutes, so its is often forgotten. I have had many optical discs come to me over the years because they show up as blank or uninitialized when read on a computer. I fear many people have put them aside or thrown them away as blank, not knowing they have data on them. Luckily with most burnable discs, you can often see the difference from a blank disc and a burned disc from the underside, writable surface.
The filesystem used on most DVD-Video discs is called UDF, Universal Disk Format. It is often combined on hybrid discs with ISO-9660 and HFS for compatibility, but can be the only filesystem as well. According to the specifications, a UDF formatted disc should have a Volume recognition sequence to identify as a UDF disk. On a finalized disc I can find this sequence, but on an un-finalized disc, it is missing. This makes sense as the the disc is often seen as unformatted. A tool I use to explore a disc like this is with ISOBuster.


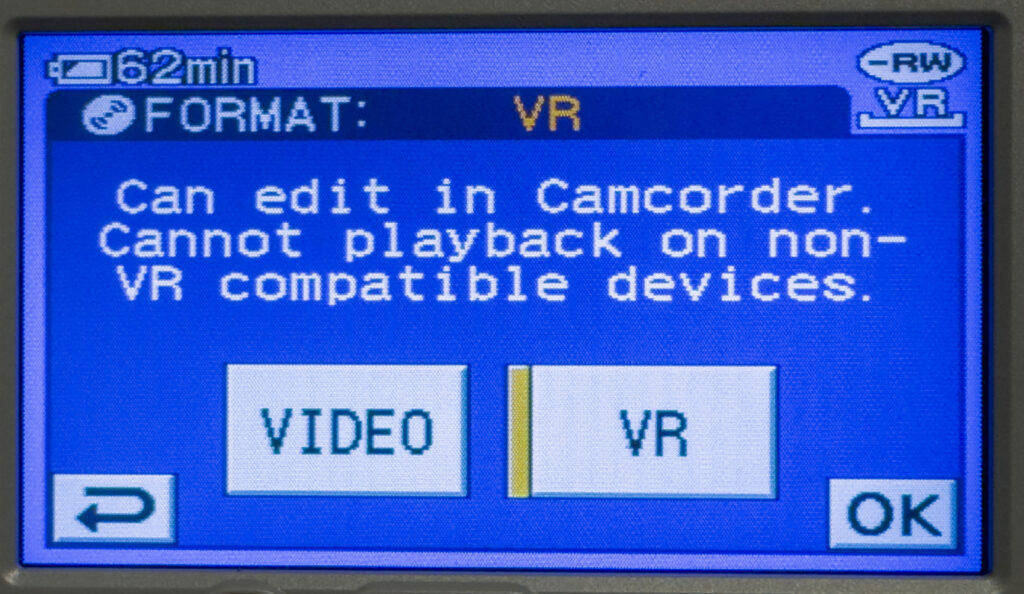
Another interesting feature of my Sony Handycam is the option to choose what type of disc you would like to prepare when you insert a blank disc. I get the option to choose Video or VR mode. Video is your normal DVD-Video format, but VR Mode is something a little different.
tree /Volumes/2025_05_23_08H29M_PM
/Volumes/2025_05_23_08H29M_PM
└── DVD_RTAV
├── VR_MANGR.BUP
├── VR_MANGR.IFO
└── VR_MOVIE.VRO
2 directories, 3 files
Instead of your expected VIDEO_TS folder, we see a DVD_RTAV folder with some different files inside. No this is a Virtual Reality mode, like I originally thought, the VR simply stands for Video Recording and is a standard. It is meant to allow for easier editing of the video format, but is not compatible with your standard DVD Player. The VRO format used is pretty cool, it is a container format, MPEG-PS, for both audio and video, also containing both 4:3 and 16:9 aspect ratios, unlike a VOB where the aspect ratio is set.
hexdump -C /Volumes/2025_05_23_08H29M_PM/DVD_RTAV/VR_MOVIE.VRO | head
00000000 00 00 01 ba 44 00 04 00 04 01 01 89 c3 f8 00 00 |....D...........|
00000010 01 bb 00 12 80 c4 e1 04 e1 7f b9 e0 e8 b8 c0 20 |............... |
00000020 bd e0 3a bf e0 02 00 00 01 bf 07 d4 50 00 00 00 |..:.........P...|
00000030 00 4d e3 00 00 00 00 00 ff ff ff ff ff 00 00 00 |.M..............|
00000040 00 00 00 00 00 00 00 00 53 4f 4e 59 5f 4d 4f 42 |........SONY_MOB|
00000050 49 4c 45 20 20 20 20 20 20 20 20 20 20 20 20 20 |ILE |
00000060 20 20 20 20 20 20 20 20 41 52 49 5f 44 41 54 41 | ARI_DATA|
00000070 01 02 ff ff 53 4f 4e 59 00 44 43 52 2d 44 56 44 |....SONY.DCR-DVD|
00000080 30 30 34 47 00 01 55 53 52 54 59 50 45 31 4c 4b |004G..USRTYPE1LK|
00000090 00 10 01 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
The VRO file does identify as a MPEG Program stream (x-fmt/386), but does contain a little extra information. My trusty copy of the book DVD Demystified has a bunch more info on this format if you are interested, you can find a copy here. The VRO format is an MPEG PS so identification is covered, but the current PRONOM signature doesn’t like the VRO extension. The BUP & IFO files on the disc are not identified. This is because the PRONOM signature, which covers both of these formats, is looking for the ASCII string “DVDVIDEO-VTS” or “DVDVIDEO-VMG”. It won’t find either of those strings as this is not the DVD-Video standard. instead it should look for the string “DVD_RTR_VMG” found in these files.
hexdump -C /Volumes/2025_05_23_08H29M_PM/DVD_RTAV/VR_MANGR.IFO | head
00000000 44 56 44 5f 52 54 52 5f 56 4d 47 30 00 00 7f ff |DVD_RTR_VMG0....|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 02 07 |................|
00000020 00 11 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000040 1e 5c 03 11 ff ff ff ff ff ff ff ff ff ff ff ff |.\..............|
00000050 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000060 ff ff 4d 41 59 20 32 33 20 32 30 32 35 20 20 20 |..MAY 23 2025 |
00000070 38 3a 32 39 50 4d 00 00 00 00 00 00 00 00 00 00 |8:29PM..........|
00000080 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
I will probably suggest this addition to PRONOM for identification, but if you need to work with this format, you can use tools like: https://www.pixelbeat.org/programs/dvd-vr