If you are looking for LUTs, you’re in luck. There is a website for sharing your FreshLUTs. Even though they are fresh, they are probably not as exciting as one might think.
LUTs are short for Look-Up Tables, which doesn’t sound as exciting as you were probably hoping. They are a pretty interesting process for dealing with color in high end Image and Video processing applications. Often called 3D Look-up Tables, they are used for color grading, an essential step in film production and restoration to map from one color space to another. LUTs are not to be confused with ICC profiles which aim for color accuracy, while LUTs are looking for more color quality and aesthetics.
There are a lot of LUT formatsout there, it seems. In looking into this format, I have found dozens of others to investigate, but today lets look at the four available as an export from Photoshop.
Above you can see a simple screenshot for the export of different formats from Adobe Photoshop. Adobe is one of the biggest developer and supporter of the formats used in LUTs, but there are many other graphics tools which create and support LUTs. In this Photoshop export we can see four formats included in the export. Lets take a look at each of these.
ICC Profiles are well documented and available for identification in PRONOM.
filename : 'LUTs-Export-s01.icc' filesize : 197024 modified : 2025-02-25T09:37:24-07:00 errors : matches : - ns : 'pronom' id : 'fmt/1975' format : 'ICC Profile' version : '2' mime : 'application/vnd.iccprofile' class : 'Dataset' basis : 'extension match icc; byte match at 8, 32'
But the other three are plain text files and still identify as such. Let us start with the CUBE format.
filename : 'LUTs-Export-s01.cube' filesize : 884963 modified : 2025-02-25T09:37:24-07:00 errors : matches : - ns : 'pronom' id : 'x-fmt/111' format : 'Plain Text File' version : mime : 'text/plain' class : basis : 'text match ASCII' warning : 'match on text only; extension mismatch'
cat LUTs-Export-s01.cube #Created by: Adobe Photoshop Export Color Lookup Plugin #Copyright: (C) Copyright 2025 ObsoleteThor TITLE "LUT-export-s01"
The CUBE format was first developed by IRIDAS in 2003 as a answer to ensure interoperability with other software. Adobe acquired IRIDAS in 2011 in a effort to be a leader in the color grading and enhancement market. They have published the CUBE specifications for version 1.0 in 2013.
A Cube file is a text file that defines a look-up table in the Cube format. The Cube look-up tables store RGB values. Advantages of the Cube format include:
The Cube format can describe look-up tables for a wide range of purposes, from simple gamma adjustments for display output to complex HDR image processing.
The format is well suited for professional digital cinema applications and for both normal range and High-Dynamic Range image processing.
As Cube files are text files, they are easily edited or reviewed using a text editor.
A Cube file can include three 1-dimensional tables or one 3-dimensional table.
The tables can be in a wide range of sizes.
Cube files are trivial to write and read.
All values are human-readable as they are in decimal form, and can be of high precision.
The input domain and output range are not limited to the range 0.0 to 1.0.
According to the specifications, a CUBE file can be a One-Dimensional Cube file or a Three-Dimensional Cube file. From the example above you can see the file is a Three-Dimensional file with the required line “LUT_3D_SIZE“. But in a One-Dimensional file, the required line is “LUT_1D_SIZE“.
cat Demo.cube TITLE "Demo" LUT_1D_SIZE 3 DOMAIN_MIN 0 0 0 DOMAIN_MAX 1 2 3 0 0 0 # Comments can go anywhere 0.5 1 1.5 1 1 1
Each CUBE file has one or the other and should be an easy string to look for. It is in a variable position as there can be comments before the required line and also may have a TITLE line. The TITLE and DOMAIN lines are common to every file but not required.
Now, the CUBE format is a bit different depending on the source. They all seem to have the same header, but different elements. It seems the IRIDAS Cube format is the most interoperable. The Truelight Cube format generally has the CUB extension, and the Cinespace Cube has the CSP extension, which will look at next/ You can read more about the differences on this format comparison table. This LUTCalc web site has many different types of Cube’s it can output, so there are some differences.
The other file format available in the export is a CSP. The CSP is also a plain text file, often called a cineSpace LUT file. This format come from the cineSpace software, a color management software for the film and television industry.
cat LUTS-s01.csp CSPLUTV100 3D
BEGIN METADATA #Created by: Adobe Photoshop Export Color Lookup Plugin TITLE "LUTS" END METADATA
The cineSpace LUT format contains three main sections. Header This section contains the LUT identifier and the LUT type, 3D or 1D. It is made up of the first two (2) valid lines in the file. See Notes below for the definition of a valid line.
So there is a pretty obvious header to work with in identification. “CSPLUTV100” can be used to identify both 1D and 3D CSP files.
The other format available to export from Photoshop is 3DL. They seem to be connected to the Assimilate Inc. company and software. A specification has been posted, and it looks like there is only ASCII and not much in the way of a header.
It does not appear there is any headers or static strings to use for identification. The specification calls the format, 3DL ASCII format and that “All lines starting with ‘#’ are treated as comments.” Because of this, I don’t think positive identification can happen at this time.
For now I am just proposing 2 new file formats to PRONOM, The CUBE format And the CSP Format. Click on my GitHub submission page to see the signatures and enjoy some samples!
Not to be confused with Fantasia, a magical screen recording tool has been around for many years. Books have been written on the use of this software to instruct others on how to teach and demonstrate other software and ideas.
Unlike Fantasia, the screen recording software Camtasia was not made by Disney, but does contain some proprietary data. Camtasia is a screen recording software by the developer TechSmith. First released in 2002, it was available first for Windows and much later, Macintosh.
The first versions of Camtasia would encode screen recordings in an AVI container, using the TSCC codec. The TSCC codec, aka TechSmith Screen Capture Codec, was developed by TechSmith and the codec was distributed freely. Let’s see what MediaInfo knows about it.
mediainfo Camtasia1-s01.avi General Complete name : Camtasia1-s01.avi Format : AVI Format/Info : Audio Video Interleave Format settings : BitmapInfoHeader File size : 1.66 MiB Duration : 2 s 333 ms Overall bit rate : 5 966 kb/s Frame rate : 15.000 FPS
Video ID : 0 Format : TechSmith Codec ID : tscc Codec ID/Info : TechSmith Screen Capture Duration : 2 s 333 ms Bit rate : 87.3 kb/s Width : 320 pixels Height : 240 pixels Display aspect ratio : 4:3 Frame rate : 15.000 FPS Bit depth : 8 bits Bits/(Pixel*Frame) : 0.076 Stream size : 24.9 KiB (1%)
The AVI video format was the default recording format for the first couple versions. In version 3 the default format changed to the proprietary CAMREC format.
Camrec video files are a proprietary TechSmith file format that is used to store multiple files and information in a single package. Overall, .camrec files store your screen and camera recording plus some meta data about the various streams. However, it is important to note that you cannot view or play .camrec files outside of Camtasia Studio.
The CAMREC video format isn’t entirely proprietary and uses a common container.
Scanning the drive for archives: 1 file, 4696576 bytes (4587 KiB)
Path = Camtasia3-s01.camrec Type = Compound ERRORS: Unexpected end of archive Physical Size = 4698112 Extension = compound Cluster Size = 4096 Sector Size = 64
Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ ..... 3912 3968 manifest.camxml ..... 4672000 4673536 Screen_Stream.avi ------------------- ----- ------------ ------------ ------------------------ 4675912 4677504 2 files
The CAMREC file might be unknown to most video players, but the AVI within the compound object is the same as the versions before it. Camtasia even has a built in extractor if you really need to pull the AVI out of the format.
Each CAMREC file contains a manifest.camxml. They seem to be UTF-16 XML files, with and without the XML declaration. The Screen_Steam.avi file seems to be in all my samples, but not clear if there can be a variant without an AVI file.
This CAMREC container was used in the Camtasia Studio software until version 8.4 when the default was changed to a new Codec, based on MPEG4, with the TREC extension.
mediainfo capture-1.trec General Complete name : capture-1.trec Format : MPEG-4 Format profile : Base Media / Version 2 Codec ID : mp42 (mp42/isom) File size : 277 KiB Duration : 3 s 41 ms Overall bit rate mode : Variable Overall bit rate : 746 kb/s Frame rate : 19.091 FPS Encoded date : 2025-02-11 03:48:25 UTC Tagged date : 2025-02-11 03:48:34 UTC FileExtension_Invalid : braw mov mp4 m4v m4a m4b m4p m4r 3ga 3gpa 3gpp 3gp 3gpp2 3g2 k3g jpm jpx mqv ismv isma ismt f4a f4b f4v
Video ID : 1 Format : tsc2-D0 Codec ID : tsc2-D0 Duration : 2 s 933 ms Bit rate : 495 kb/s Width : 924 pixels Height : 696 pixels Display aspect ratio : 4:3 Frame rate mode : Variable Frame rate : 19.091 FPS Minimum frame rate : 10.000 FPS Maximum frame rate : 30.000 FPS Bits/(Pixel*Frame) : 0.040 Stream size : 177 KiB (64%) Title : 100 Encoded date : 2025-02-11 03:48:25 UTC Tagged date : 2025-02-11 03:48:34 UTC
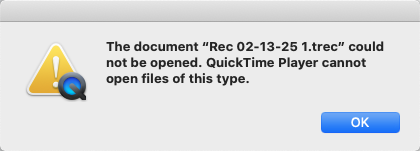
TechSmith Recording File (TREC) files will identify as an MP4 in most identification tools, you will need MediaInfo or other tools to understand the codec used. If we look at the header of the MP4 TREC file:
We see the standard header for an MP4 file. The codec specific to the Camtasia software is identified later in the file, but identification using a PRONOM signature might be challenging. In looking at the hex of the file, near the end, you can find embedded PNG’s and other data. VLC and FFMPEG can read the codec, but players like Quicktime struggle.
A promising section near the end shows the name and version of Camtasia Studio. More data needed.
Camtasia also uses a lot of Project files to managing the video editing process of your screen recordings. The project files can vary between the Windows and Macintosh versions.
The older versions of Camtasia for Windows up until version 8.4, used the CAMPROJ extension for their projects. These are in XML and simply use “<Project_Data>” for the root element. With Version 8 having a later element “<CSMLData>” to manage the assets. Other projects also have a File element that begins with either “tscrec4://” or “TSCRec://”. But it may be best to identify the older versions with the “<ClipBin_Array>” element.
For Mac version 2, they used CMPROJ for the Project, but also it was an Apple Bundle/Package file. It also used a recording file with the extension CMREC, but is also Apple Bundle/Package file which contains MOV and DAT files.
The most recent versions of Camtasia for Mac and windows use the TSCPROJ extension. They are plan text files with some resemblance of JSON.
There are a few formats related to Camtasia, but the CAMREC format is the one that shows up the most in my work. So today I am only proposing a signature for CAMREC and the CAMPROJ formats. We will have to have some discussion on the TREC format to determine if standard MPEG-4 identification is fine or if the format needs its own PUID. You can find some examples and my proposed signature on my Github page.
One of the most important software titles related to professional audio recording and mixing is Pro Tools. The Digital Audio Workstation by Digidesign, now Avid, has been around since 1991 and was born from the very popular Sound Designer software first released in 1985. When Sound Designer II was released a few years later, the audio format used became the standard file format for audio recordings. Pro Tools progressed from there to become the industry standard for professional audio production, even winning a Technical Grammy, Emmy, and Oscar.
Pro Tools helped produce amazing music for artists such as No Doubt, Maroon 5, Ricky Martin, and many others. Obviously the best part is the final mixed audio used to make the music we love, but the work that goes into creating the audio mixes is saved in a Pro Tools session. The session is where all the magic happens. A Pro Tools session is actually a project file within a folder where all the supporting files are located.
These Session “Folders” can get pretty complex as more audio and effects are added to the session, adding folders such as Fade Files, Rendered Files, and Plug-in settings. The current version of Pro Tools uses a project session file with the extension PTX, but that wasn’t always the case. The current version of Pro Tools can be run on Macintosh and Windows, but that also was not always the case. Because the software was originally written for Macintosh hardware, the session files were only compatible on the Macintosh file system as well.
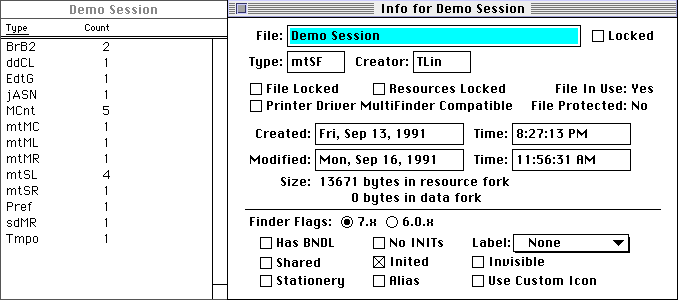
You might notice the “Demo Session” file is Zero Bytes, but the Resource Fork is 13671 bytes in size.
The Pro Tools Sessions from the beginning until version 5 used this method of storing the session data. ALL in the Resource Fork. Because the session data was in the resource fork and the supporting audio files were in the Sound Designer II format, which also stored important information in the resource fork, this made it impossible to use on anything but a Macintosh file system.
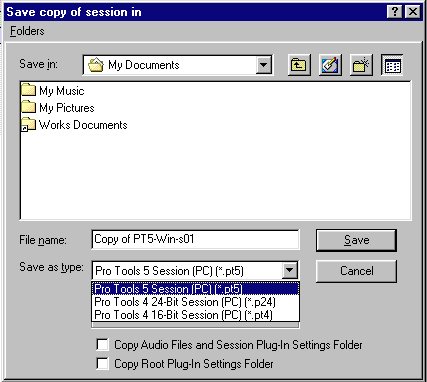
Version 10 of Pro Tools allows you to export the full session back into older versions of the software to version 3.2. When you choose version 5 on a Mac, it forces you to also convert the audio formats to SD2 files as well. For versions 1 & 2 of Pro Tools, there was no official extension for the session files, but starting with version 3, you might often find the extension PT3, then PT4, and PT5. With version 4, there was also a version P24 extension used when Pro Tools version 4 made the leap to 24bit. But for each of these versions identification is not possible with current preservation tools like PRONOM. You could encode the session as a MacBinary to retain everything for modern systems, which is identifiable, but you could also use my proposal for a lookup in the TCDB python tool located here.
python3 TC-lookup-draft-uni.py "PT Session 02-41.pt4" Type Code: PT4S Creator Code: PTul Size of Data Fork: 0 bytes Size of Resource Fork: 14003 bytes Rows with Type Code b'PT4S' and Creator Code b'PTul': Row index: 32813 File Name: Pro Tools 4 Type: PT4S Creator: PTul Extension: pt4 Data by Ilan Szekely, Jerusalem: nan
Extension
Version
Type
Creator
Pro Tools 1.1
mtSF
TLin
Pro Tools 2
PSes
PTul
PT3
Pro Tools 3.2
PSes
PTul
PT4
Pro Tools 4 16bit
PT4S
PTul
PT24
Pro Tools 4 24bit
PT24
PTul
PT5
Pro Tools 5
PT5S
PTul
PTS
Pro Tools 5.1-6.9
PTS
PTul
PTF
Pro Tools 7-9
PTF
PTul
PTX
Pro Tools 10+
PTX
PTul
There isn’t a lot of information about when Pro Tools was made for Windows. I found some references to a Windows NT version of the 16bit and 24bit version 4. I did also find a copy of the free Pro Tools version 5.01 for Windows 98. In the Read Me it states:
Cross–platform File Exchange is not supported in this version of Pro Tools FREE
File interchange between Mac and PC versions of Pro Tools FREE is not possible in this 5.0.1 release. We hope to include this functionality in a future release of Pro Tools FREE.You can exchange files with Pro Tools LE and TDM users who use the same platform (Mac or Win98/Me) as you, but remember, Pro Tools FREE is limited to 8 audio and 48 MIDI tracks.
Running the software confirms the session file for this version has the extension PT5 and not the later PTS for version 5.1. This version of Pro Tools also allows you to save back to the P24 and PT4 versions, which are probably the first Windows versions. But they are entirely different file formats from the Macintosh versions.
Starting with Pro Tools 5.1 in 2001 things began to change. Pro Tools has always been tied very closely with hardware and software so with Apple launching Mac OS X, this provided an opportunity for DigiDesign/Avid to revamp their hardware and software for better compatibility and this included a cross-platform session format.
Pro Tools 5.1 used a new session format which used the extension PTS. Let’s take a look at a sample.
hexdump -C PT Session 02-51.pts | head 00000000 03 30 30 31 30 31 31 31 31 30 30 31 30 31 30 31 |.001011110010101| 00000010 31 00 01 3d 6e 1c 06 eb d8 c1 aa 16 fd 65 4e 6d |1..=n........eNm| 00000020 23 09 96 db c4 ad 95 7f 68 5d 3a 23 0c a5 ac a8 |#.......h]:#....| 00000030 90 cd ed 04 38 4e 06 47 bc e2 ca b3 9c 8f 6e 57 |....8N.G......nW| 00000040 40 2a 12 fb e4 c4 b6 9f 88 77 5a 43 2c 24 ce c9 |@*.......wZC,$..| 00000050 e3 97 9b 8a 73 5d 46 2f 4a 64 86 b6 dd d6 eb 77 |....s]F/Jd.....w| 00000060 76 49 32 1b 54 9f b9 9f fc fe 15 0f 3f 15 4d 62 |vI2.T.......?.Mb| 00000070 83 aa ab c4 fa 5d 20 26 54 44 0b f3 d9 c5 ae 97 |.....] &TD......| 00000080 cd 08 31 74 77 0d f6 df c8 b5 c0 8b 6c 7c 3f 27 |..1tw.......l|?'| 00000090 10 9e c2 cb b4 9d 86 45 58 41 2a ad e1 78 2d b4 |.......EXA*..x-.|
The session is a new proprietary binary format with an interesting header. There is one byte and then a sequence of ASCII characters in the form of a binary string. 0010111100101011 What it means is unknown to me. In Decimal, the binary reads “12075”, or hex values “2F2B” or in text “/+”. Regardless of what it means, this header was used from versions 5.1 through 9. The extension changed to PTF with version 7-9, but the header is the same. This is why PRONOM PUID fmt/1951 refers to both extensions covering 5.1-9.
It might be possible to look closer at the two extensions and find something which can distinguish between them, but because they are in a proprietary binary format, there isn’t much to go on. There has been a few attempts at reverse engineering the formats, but they even choose to lump the two extensions together.
The other import byte in this header is the second byte after the odd binary ASCII sequence. Above highlighted in purple. 0x01 is important because in the next version PTX, this changes to 0x05, highlighted below in purple.
Pro Tools version 10 was a big release, it added new features and started to phase out the HD hardware. With this release we see a new session format which is still used by the current version of Pro Tools.
This new session format has the same binary ASCII string, but a lot more plain text in the header and throughout the file. This gives us more to explore and understand with even listing the linked Audio files and their paths. PRONOM has this new format assigned to PUID fmt/1727. The signature for these files is the same sequence as the previous version, also the 0x05 byte, but with a couple additional bytes, 5A010004, after the main sequence. I am not sure of the bytes significance, but they are in all the samples I have, even from the current version.
Pro Tools has some other formats which go along with their sessions. One I’ll highlight is the Groove template format. They end with the extension GRV. You can see some samples here. They also have the odd binary ASCII header, but with 0x00 for the second byte after the main header. Highlighted in purple below.
Other extensions associated with Pro Tools which use the same format are: PIO, PIM, PTT, PTXT, RGRP.
Pro Tools has always been software directly tied to audio hardware and system software. In addition they also used software dongles to control software licensing and the licenses were not cheap. Because of this, trying to use older versions is very difficult. Finding samples for each version is difficult as each version allows for a variety of features that may not be available in another version. Luckily, there are some older “Free” versions out there with limited features we can get some ideas of the session format.
PRONOM has working identification for the two major formats and until PRONOM can incorporate Macintosh Resource Fork identification it will have to do. The PC version 4 and 5 formats could use more research as I only have one source. The groove and other formats all seem to have the same header so they will need more research as well. Until then, enjoy some sample files and also a disk image of some older Macintosh Pro Tools 3 sessions.
A few of you may remember a couple years ago reading in a Vice article about Eric Roth and his use of an old DOS only software program for writing all his Hollywood scripts. The Vice article was based on some earlier reporting in 2014 about his writing process. You can watch the full interview of Eric Roth on YouTube.
I remember seeing a link to the Vice article a couple years ago and finding the screenwriters use of an old DOS program, Movie Master, funny and interesting. He says in his interview that out of half superstition and half fear of change he prefers to use this very old software to write his screenplays. It’s so old and obsolete, he can’t even email the files to Hollywood. He has to print them out and have the studio scan them into modern software for use. The interview shows the screen of his old Windows computer and you can see the software he is using.
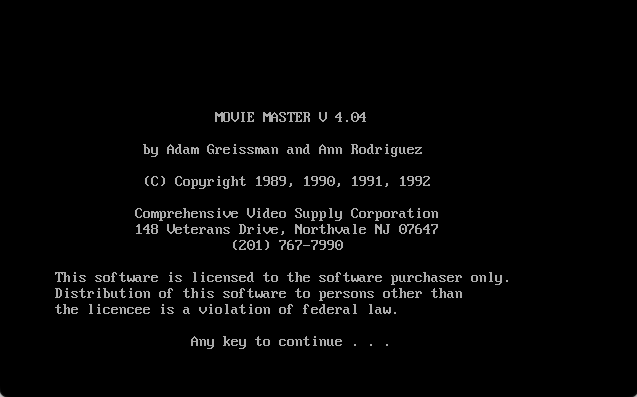
Of course because I love researching obsolete software and formats so much, I wanted to know if the scripts generated by “Movie Master”, version 3.09, are in a format that needed to be documented. I was a little surprised that this version of Movie Master was no where to be found. It was on none of the old abandoned software sites. Not on Internet Archive, no where it seemed. I did find a later version of Movie Master, version 5, but found this software was not the same thing.
The original programmer of Movie Master was Adam Greissman, which you can clearly see in the screenshot above. The software was copyright Comprehensive Video Supply in the 1980’s, but the Movie Master version 5 was developed by Ballistic Software, Inc, which was also known as “Comprehensive Cinema Software” or “Hollywood Cinema Software” later in the 1990’s.
According to a very in depth article by Daniel Plagens, Reinventing the Typewriter, mentions Adam Greissman not wanting to move the software from DOS to Windows as he didn’t feel there was enough of a market at the time. As it turns out the founder of Comprehensive Video Supply, Jules Leni, got a lot of pressure from users of Movie Master after Greissman, who left the company in 1991, to develop a Windows and Macintosh version of the software. They released this new version in October of 1996.
Let’s take a look at a couple of example files from version 5.
Version 5 of Movie Master uses the extension SCR, which one could assume is short for “Script”. There does appear to be a header before any readable text starts, so that will be helpful in identification. Currently there is only one PUID, x-fmt/100, in PRONOM with the extension SCR, which happens to be for an AutoCAD script and has no signature, so anything you ask DROID or Siegfried to identify with the SCR extension will default to an AutoCAD script, which is frustrating. According to the File Format Wiki, there are quite a few formats with the SCR extension. More work to be done there for sure.
So I tried for a few weeks to find a copy of Movie Master version 3.09, I even put in a eBay favorite search for the name so it would alert me to a copy being sold, but no such luck. I gave up for awhile, then recently someone posted a link to a large collection of early warez. Warez is the name given to software that has been illegally copied. When I followed the link and searched though the vast amount of software titles, I got excited to see a couple matches to “Movie Master”. After a little wrangling of some downloads, I spun up a copy of DOSBox and low and behold, Movie Master 3.09!
A lot of people have compared the old DOS scriptwriting tools to early word processors like Word, Perfect Writer, WordStar, etc. They did much of the same thing, but with special controls for helping with scenes, characters, indents, and everything writers needed to make some of the best Hollywood films out there. As Daniel Plagens noted:
The program proved popular for many years. Greissman estimates they sold over 10,000 units—“saturating the market,” as he put it—and recalls seeing help wanted ads in Hollywood Reporter and Variety where knowledge of Movie Master was a hiring requirement. He visited the sets of Days of Thunder and Hunt for Red October to help their writers and production teams acclimate to Movie Master.
Makes me wonder where all the old scripts from Hollywood movies are located in their electronic form? I am sure Eric Roth probably has quite the collection of different scripts he has written. I sure hope he backs them up and donates them to a library in the future.
Well, let’s take a look at a couple sample files from Movie Master version 3 and version 4. Version 4.04 was also in the collection uploaded to Internet Archive.
The first thing to notice is they all start with the version number of the software which wrote the file. Really nice to have, but a terrible magic header. The files also all begin (after the version number) and end with the Hex value “0A”. Which happens to be a line feed control character. So super common, but could be helpful. Another pattern is that on the 9th byte it is “31” on most of the samples and “36” on one of them. “31” is the start of the ASCII number sequence, so could be the sequence number for the script as each SCR file could only store what was in memory.
I fear the rest of the format will have the same issue most word processors had at the time which is not having a header, but lots of formatting codes which may or may not be in every file, making programatic identification difficult. Might take awhile to identify all the formatting codes, but could lead to better identification and possibly an import module for tools like LibeOffice or Final Draft.
I didn’t find much different with Movie Master 4, seemed to have the same restrictions to 16 files in a script. The files from version 4 also seem to follow the same patterns from version 3. But both versions are different from the the Windows version of Movie Master, version 5. Click here for Movie Master 5 help menu on “Introduction for Movie Master DOS Users“.
There was another elusive script writing software title which adds to the confusion. Scriptware was another screenwriting software tool which seems to have had a large following. They produced a Windows and Macintosh version. It also started out for DOS and also used the SCR extension. The website is still active for the software, but hasn’t updated in 24 years. I wrote a little about in my post on PROmotion. All the demo versions out there are not useable demos, but animation demos. In this nice batch of old software on the Internet Archive I was able to find an early copy. Wasn’t able to get it to run, but the folder did have some samples.
Luckily, they make it quite easy to identify these SCR files. ScriptWare was very popular and continued on with Windows and Macintosh versions. Later on, the format was changed along with the extension, which changed to SW3.
The SCR extension has been used often. On my desktop they default as a Paintbrush document. Apparently SCR is sometimes used as an extension for the ZSoft Paintbrush (PCX) format. It is also used on older postscript fonts on the Macintosh as a Type 1 screen font. Can also be a screensaver on Windows, but watch out, they can hide malicious code. You get the idea, SCR is a very common extension, identifying it up front can help avoid problems later!
Moral of the story is to never give up searching for old software and even though illegal copying of software should be avoided, I am grateful to those who help save abandoned software. Without them many titles would be lost.
I don’t have a good signature for these formats yet, but you can find a few samples on my GitHub page.
Receiving electronic media from an outside source can be an adventure. Often times you find yourself sorting the valuable files and separating them from the chaff. There can be hidden files, cache files, application files, drivers, and everything in between. Determining what formats are important can sometimes be difficult, especially if you don’t know the file format of some of the files.
I was recently working on a collection of files which had been produced through some audio software. When working with audio, a WAVE file is what is usually kept as they contain the actual audio data. With these files they came with a couple other formats. One of those formats was a bunch of SFK peak files. These files are meant to be temporary as they are generated from the WAVE file to make opening of audio data faster. They are important, but can easily be regenerated. One could argue they have historical value, but also they don’t contain anything that can be used by itself, so alone they don’t have much value.
The other format found with the WAVE files have a CDP extension. These came up as unknown when using DROID. It is not a common extension so finding the name of the software which created the files wasn’t too hard. Let’s take a look at one of them.
Huh, this is a RIFF file. RIFF is most commonly used as the container used for WAVE and AVI files. You can read more about the RIFF format on a previous post. The RIFF container format can be used for all sorts of things. Looking at the internals we can see a few unique list chunk’s.
Lots of references to other files, specifically WAVE files. But not a lot of actual data. That is because this format turns out to be just a project format for some software called “CD Architect“. Sonic Foundry was an audio software developer for a few years before they sold their catalog to Sony in 2003. In looking at the manual for CD Architect version 5.2, it explains the CDP Project format.
CD Architect software handles the organization of your CD using a small project file (CDP) that saves information about source file locations, edits, cuts, and insertion points. This project file is not a multimedia file, but is instead used to create the CD when editing is finished.
Looking at another CDP file from the collection, I noticed something different.
That’s odd, the RIFF format is always uppercase ASCII, this is lowercase. Also the important RIFF form, which was “SFPJ” in the other sample, is missing. This is not a valid RIFF format.
But further down in the file I can see the same list chunks. Did they take RIFF format and make a proprietary version of their own? I think they may have. It seems the first example was from CD Architect version 4 and these other files are from CD Architect version 5. That complicates things. Sony stopped developing CD Architect after version 5.2d and maintained it for a few years before selling many of their titles to MAGIX Software. As far as I know there was never any new versions released. The software was very popular, as it had some really nice audio mastering features and was easy to use. Many were upset when the software was abandoned.
Creating a signature for both version 4 and version 5 CDP files will be pretty straightforward. I feel knowing what you have in a collection you are processing is the first step in making informed decisions. Wether or not you keep the project files are up for debate. Some may only want the final audio created from a CD Architect project, while others may want to see the way the audio was put together and mixed. Either way, the more you know…..
One more thing. CD Architect would default to saving a CDP project file, but could also save a “CD Image file”. This process actually would save the project to a full WAVE file with some extras baked in.
An image file is essentially a wave file with volume, crossfades, effects, mixes, and track information embedded. Burning an image file will reduce the risk of buffer underruns (especially if you have a complex project or are using a slow computer) since no audio processing is required.
Interesting, normally when working with track information in a single WAVE file you would need a companion CUE Sheet in order to reference the track layout of the Audio CD. So I am curious how they do all of this. Lets take a look at a “CD Image”.
mediainfo CDArch52d-s02.wav General Complete name : CDArch52d-s02.wav Format : Wave Format settings : PcmWaveformat File size : 5.05 MiB Duration : 30 s 0 ms Overall bit rate mode : Constant Overall bit rate : 1 411 kb/s Conformance errors : 2 RIFF : Yes General compliance : File size 5292434 is less than expected size 5292823 (offset 0x8) WAVE : Yes General compliance : Element size 5292811 is more than maximal permitted size 5292422 (offset 0xC)
Audio Format : PCM Format settings : Little / Signed Codec ID : 1 Duration : 30 s 0 ms Bit rate mode : Constant Bit rate : 1 411.2 kb/s Channel(s) : 2 channels Sampling rate : 44.1 kHz Bit depth : 16 bits Stream size : 5.05 MiB (100%)
Already seeing some issues with the format, but all the important bits are there. JHOVE doesn’t like them much either.
JHOVE is giving me two issues. The major error is the file appears truncated according to both MediaInfo and JHOVE. The InfoMessage which is less of an issue but more of a heads up that the WAVE file has an extra LIST type. “PQLS”, which was also in the CPD RIFF file we looked at earlier. So it seems by making a “CD Image” of a project embeds the project chunk data into the WAVE container. Identification is not an issue as these WAVE’s follow the standard pattern and therefore identify correctly, but one might want to be aware through further characterization these WAVE’s have some not so obvious extra data.
My attempts to find any samples from version 3 of CD Architect have failed. Until then, my proposal is to add version 4 & 5 to PRONOM with the signature on my Github page. There you will find a few samples as well.
This T-Shirt Factory Deluxe files are a bit of an extreme, probably a prank against all of us doing file format identification. If you know who made this decision, I would like to have a chat.
This is not first time I have come across a format which seems to have been used for more than one software title. Awhile back I tried to find more information on a file format used with many tools created by MetaCreations. It was called “Composite File Management System“, and was used with Kai’s Power tools, Bryce3D, Ray Dream, Poser, and others. I did a previous post about the format.
I came across another recently with a similar issue. They are also many different software titles with the same native format.
NCH Software is an Australian software company who produce a massive number of software titles covering many different needs. From Audio Editing to Business charts and from Accounting tools to a 3D model converter, they have it all. Their audio editing software WavePad is quite popular. My initial entry into their software world was for the specialized Dictation/Scribe software which produced a slightly proprietary audio format with the extension DCT. This format does not use the format many of the other titles use.
With the number of different titles, it probably makes sense they use the same file structure to make processing/programming more efficient. They appear to be mostly proprietary binary files.
Above are just a few of the titles which use the same structure. The LSDF string is the first 4 bytes and always the last 4 bytes. The next two bytes, 0100, seem consistent for all samples, but the two bytes after that seem to be unique to the software. So far I have found the following titles use the format.
Without downloading and installing their vast library of software it’s hard to know all the different titles which use the format. The rest of the file for each sample seems to be proprietary in a binary format, except a few with a PNG image mixed in.
The simplest sample I could find was a preset file for the Zulu DJ Software which uses the ECF extension. The ECF extension is common with a few of the titles, like effect chains for WavePad and MixPad.
This header is identical to the header for the VOXAL format, so not sure if the second set of 4 bytes is directly connected to the software title. Or if there purpose is something else.
The question that needs to be answered is how we might represent these formats in PRONOM if needed. We could create a unique signature for each title based on the magic header and footer and the second set of 4 bytes which may indicate the software. Or create a single generic signature to identify the basic format using the magic header and footer and adding all the extensions to the list, which would be lengthy. This would be the easiest and catch all formats related to NCH Software using this file format, but then additional characterization would need to happen to identify the specific software title needed to render the file.
The NCH Software company seems to churn out new software and versions quite frequently and a search for reviews of their software turns up some questionable results. Many might enjoy their software as they are easy to use and are free for home use. I had lots of trouble with a few of them as they wanted to mount network locations and disk images I had used recently, which seems sketchy. I would love to know if anyone uses their software and has any need to preserve these formats. I currently don’t, but found the common use of a file format intriguing. I also found no reference to the magic bytes they use, except for a few TrID entries. Marco always is a step ahead!
Years ago I bought my first digital camera. It was an Epson PhotoPC 3100z and I bought it because it could capture a digital image directly to a TIFF file. I don’t think most people would care about such a feature, but I thought it was awesome. Granted it filled up the small 32MB compact flash card pretty quick, I had to upgrade to a 512MB card, that set me back.
TIFF images are pretty universal, they have a well known structure and have been around for a very long time. I have written about TIFF’s before, so I wont go into too much about the format. The format is well respected in the preservation community, although one of the best websites, Aware Systems, documenting the various TIFF tags has gone dark in the this year, here is an archived version.
Many of the digital camera’s from the beginning to now use the TIFF format to store RAW sensor data. Most use their own extension and follow well established methods for storing the sensor data in an IFD with lots of common and custom tags. The DNG format is an open RAW format which uses the TIFF format to store sensor data, although many use SubIFD’s and can be incompatible with some software.
The first Digital Camera was invented by a Kodak employee, Steve Sasson in 1975, well, he was the first to use a CCD sensor in a self contained unit. This led Kodak to push the technology forward and in 1991 released the Kodak DCS digital system which used Nikon cameras equipped with a digital sensor. These early digital cameras were quite expensive, they used early CF cards and SCSI connections. Kodak released a few models of the DCS series, first on Nikon bodies, then on some Canon bodies. These early cameras used the TIFF format to store the RAW sensor data. For some reason, they decided to use a proprietary method and compression while still using the TIF extension.
Kodak was responsible for many new image file formats. Not sure why they decided to use a common format like TIFF and still use the TIF extension, but make it proprietary. The RAW file created by the DCS series of camera’s had to be opened with special plugins or software, if you tried to open the TIFF’s with anything else, you would only see the small thumbnail image located at IFD0 instead of the full size image hidden in a SubIFD1.
Finding samples of this format is particularly hard as they have the common TIF extension. The camera’s are also pretty rare and finding one is difficult, especially in working condition. I was only aware of a couple samples on the rawsamples.ch site, but that wasn’t enough to understand the format as the two files had a different structure.
There is/was a website called https://raw.pixls.us/, but it has been offline since last June, the regular site still works, but the raw sub-domain is unreachable. Luckily the wayback machine had archived a few samples.
I also found a reference on an older website referring to a sample set maintained by Kodak for developers using the SDK, but also no longer available. You can find the old website also on the wayback machine.
With a few more samples to refer to, it makes it easier to understand the headers and put together a signature. There was an SDK, but seems to be difficult to locate today, but the manual does give us a little more info on the different models and their format.
So from the SDK statement, the samples I have in TIF, and others I have in the more recent DCR format, I can conclude the custom TIF format was used with the DCS 3xx, 4xx, 5xx, 6xx models and from 7xx on the DCR format was used as the camera RAW. Looking closer at the samples in TIF, we can see all the 4xx models used the “FILE VERSION 3” version of the format, while the others have the full statement in the header. Not 100% clear on which format came first, but the 4xx models are some of the earliest models.
At the time, there was only Kodak software that could properly “develop” the RAW file taken by these camera models. Today that has changed and the format has been added to many open source libraries such as libraw and rawspeed. Many other commercial products also claim to support the DCS models including Adobe Camera Raw, which seems to be able to open these TIF’s.
Distinguishing these RAW TIF’s is important to properly manage them over the long term. These images currently identify in the PRONOM repository as regular TIF’s, fmt/353, so we would need to create a signature which identifies the standard TIFF header, but also uses bytes unique to this format. In the few samples I have the “VERSION 3” images all start with the litte-endian header, “49492A00”, while the other samples start with the big-endian header, “4D4D002A”. That makes it a little easier for each signature.
For for the “VERSION 3” format we could use a pattern such as 49492A00{12}4B4F44414B{11}(444353|454F53444353). This looks for the TIFF header, skips 12 bytes, looks for the word “KODAK”, skips 11 more bytes to then look for either “DCS” or “EOSDCS” right before the camera model number.
For the other format we also look for the TIFF header, but then find the whole string used in all the samples. 4D4D002A{60}5468697320696D6167652066696C652077617320637265617465642062792061204B6F64616B20444353{5}6469676974616C2063616D6572612E
This looks for the big-endian header, then the string, “This image file was created by a Kodak DCS”, skipping the model number, then the end of the string, “digital camera.” This should catch all the different models of this format.
You can find my proposed signature on my GitHub page, since none of the samples belong to me, you can find them above in some of the links.
For #WDPD24 and PRONOM Hackathon week this year, I want to find some older formats listed which did not have a signature. There is a list to choose from, but I wanted to find something I hadn’t worked on before. I came across two entries for Real Video:
PUID
Name
Extension
fmt/204
RealVideo Clip
rv
x-fmt/277
Real Video
rv
I was familiar with Real Media and Real Audio, but had yet to come across any RealVideo with the RV extension. I thought it would be easy to find some references and samples, but that was not the case. I assume PRONOM originally added these based on MIME types available.
Real or RealNetworks is/was an Internet media company who jumped on the rapidly growing World Wide Web in 1995 to become a leader in Internet Media Delivery. Their initial offerings mainly focused on audio streaming and they accomplished all of this by providing free players and web browser extensions to make it easy to serve up a website with streaming media everyone could enjoy. Later adding video streaming optimized for the slower dialup and connections of the day. They used codecs based on common technology like H.263 and H.264, but used then to make their own proprietary codecs identified through FourCC codes, RV10-RV60.
So thought it would be easy to find a reference to the RV extension, I quickly discovered it wasn’t. Looking at the Wikipedia page on RealVideo, I found no reference to the RV extension. RV is an abbreviation for RealVideo, right? Well, I ended up finding a reference in the RealAudio page under file extensions. Ok, First clue to the existence of the RV extension. The page references RV as being used for video only files and was used by the flagship encoder (RealProducer).
RealProducer was the tool for creating the streaming audio and video formats that could then be used for your website or streaming platform. The RealProducer software came in a Basic version, which was free, and the Plus or Pro version, which was not free and provided more options. The first version of RealProducer to make video files was version 4. I was able to find a copy of the encoder and installed it under a Windows 95 emulator. To my surprise it only saved to the RealMedia RM file format. This format is well known and identified with PRONOM as x-fmt/190 also documented at the LoC.
This was the same with RealProducer 5, 7, 8, 9, and 10 that I was able to try. All made no mention of the RV extension. I was starting to feel this format didn’t exist or that some decided to use the RV extension on their own. Searches on Google yielded a couple results, mostly from users who had found a few files on their older discs and wanted to migrate them to something newer. I was able to find one example, one user shared, but it had the same header as the RealMedia format. The clue was in the file.
RealProducer Basic 11 for Windows. The Wikipedia article did hint at this by saying “the latest version of RealProducer reverted to using .ra for audio only files and began using .rv for video files with or without audio.” Why would they use the RM extension for so long, then revert to a different extension with a later version? I found more in the User Manual for version 11.
• .rv – RealVideo RealProducer uses the .rv file extension if the input is video-only or video-with-audio. You can also select the .rm file extension for video content. Tip: Using the .rv file extension helps search engines identify the file as a RealVideo clip.
• .rm – RealAudio or RealVideo RealProducer chooses the .rm file extension if it cannot determine the content of the input clip. You can use .rm file extension for any RealAudio or RealVideo clip, except for variable bit-rate clips.
Ok, so a few things to learn from this. One is the RV extension was used as the default for version 11 as they wanted search engines to identify them as a RealVideo clip. Second thing we learned is there is no difference between the two placeholders in PRONOM, one being a RealVideo file and the other being a RealVideo Clip. We don’t need both.
Now, is there any difference between an RV and RM file?
They both look very similar to me. Aside from a few bytes, they are practically identical. Lets see what MediaInfo has to say.
mediainfo Producer11-01.rv General Complete name : Producer11-01.rv Format : RealMedia File size : 164 KiB Duration : 6 s 999 ms Overall bit rate : 225 kb/s Frame rate : 24.000 FPS Copyright : (C) 2005 FileExtension_Invalid : rm rmvb ra
Video ID : 0 Format : RealVideo 4 Codec ID : RV40 Codec ID/Info : Based on AVC (H.264), Real Player 9 Duration : 6 s 999 ms Bit rate : 181 kb/s Width : 640 pixels Height : 424 pixels Display aspect ratio : 3:2 Frame rate : 24.000 FPS Bits/(Pixel*Frame) : 0.028 Stream size : 155 KiB (94%)
Audio ID : 1 Format : Cooker Codec ID : cook Codec ID/Info : Based on G.722.1, Real Player 6 Duration : 7 s 429 ms Bit rate : 44.1 kb/s Channel(s) : 2 channels Sampling rate : 44.1 kHz Bit depth : 16 bits Stream size : 40.0 KiB (24%)
mediainfo Producer11-01.rm General Complete name : Producer11-01.rm Format : RealMedia File size : 151 KiB Duration : 6 s 999 ms Overall bit rate : 225 kb/s Frame rate : 24.000 FPS Copyright : (C) 2005
Video ID : 0 Format : RealVideo 4 Codec ID : RV40 Codec ID/Info : Based on AVC (H.264), Real Player 9 Duration : 6 s 999 ms Bit rate : 181 kb/s Width : 640 pixels Height : 424 pixels Display aspect ratio : 3:2 Frame rate : 24.000 FPS Bits/(Pixel*Frame) : 0.028 Stream size : 155 KiB
Audio ID : 1 Format : Cooker Codec ID : cook Codec ID/Info : Based on G.722.1, Real Player 6 Bit rate : 44.1 kb/s Channel(s) : 2 channels Sampling rate : 44.1 kHz Bit depth : 16 bits
Other than the RV file having a invalid file extension, they both identify as a RealMedia file and have identical properties. So it seems the RV file is really no different than the RM file. I think the best course of action for PRONOM is to deprecate these two RV PUID’s and just ad RV as an acceptable extension for the RealMedia format.
To add to the evidence, here is the output from ffprobe:
But wait, there are a couple formats we could add which are related to RealProducer. RealProducer used a few other formats to manage projects and other metadata for streaming. They include:
Don’t get excited, the RealPix Image format really isn’t an image, it is simply an XML file with all the details of an image or group of images. Pretty boring. It was however a big thing in the day, even got a full guide written up for the process. “All information in the file occurs between an opening <imfl> tag and a closing </imfl> tag. This is the only tag that uses an end tag.” This format was the topic of discussion as malicious code could be in the RP file and executed just by having someone load your webpage. IMFL is obviously an acronym, but none of the documents I could find tells me what it stands for, so I did what everyone does now, I asked ChatGPT.
The RealPix format by RealNetworks, which was used for interactive multimedia content, indeed utilized IMFL as its tagged format. IMFL stands for “Interleaved Media File Language.” This markup was particularly designed to handle multimedia presentations, allowing the synchronization of images, audio, and video in a slideshow-style format. It used XML-like syntax where elements like <imfl>, <head>, and <fadein/> defined media objects, transitions, and their timing. Key components included attributes for positioning, color, and animation effects, making RealPix a flexible format for creating multimedia sequences compatible with RealPlayer.
For technical details, the RealPix format closely resembles SMIL (Synchronized Multimedia Integration Language) and supports strict tag closure and case sensitivity. This means all tags and attribute names must be lowercase, and attributes must be in double quotes, as seen in SMIL and RealSystem G2 markup, RealNetworks’ broader multimedia framework.
When I asked for a source, it could not give me one. So not sure if it is the correct answer, but it seems to fit. Here are some samples of RP, RT and SMIL files.
For RealText with the RT extension, we find a similar tagged text. This format is used to provide text presentations to go along with Images, Audio, or Video. The tagged text then describes when and how the text is displayed. This is all done in a player window, therefore the root tag of these RT documents starts and ends with <window>. I guess these could be considered a subtitle format for streaming media.
The SMIL files is interesting, it is known standard, but in many cases, does not have an XML declaration, therefore not identified by current PRONOM. They are used to link everything together. I might suggest a variant of the SMIL format to not have the XML declaration to identify these formats correctly.
The .RPAD RealProducer Audience File, .RPJF RealProducer Job File, .RPSD RealProducer Server Destination are all XML files for managing some of the configuration found in the RealProducer software.
Those three formats should be easy enough, especially if we look for Namespace urls.
The RAM and RPM formats are simply text files with a URL. You can find some samples here and here.
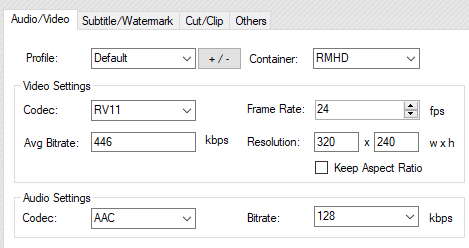
An RM and RV file are the same format as the RMVB file but just with a variable bitrate. Later on a new format was used to improve the quality of video. This format has the extension RMHD, referring to RealMedia HD. Let’s take a look.
The format looks very similar, but has the magic header of .RMP instead of .RMF. MediaInfo and FFProbe are unaware of the format. The software mentions a RV11 codec which is confusing as the codecs went from RV10-RV60.
Phew, that was a lot considering the two formats I tried to research came up the same as an existing format. There are probably others I have missed. I did see a reference to an RMX format which seems to be an encrypted RM file. The header is the same so it will identify as a RealMedia file, but with the wrong extension. Let me know if you come across any. I have some samples of the formats mentioned here, plus a proposal of new signatures on my Github repository.
Some file formats have a unique extension. Some formats use three character extensions which are well known, so its not common for them to be used with other software. Take the extension PDF for example, pretty sure no one else will use it as it is so well known. Other extensions often get reused by a few different software titles. There are plenty of titles which use the DOC extension.
Part of defining a file format I come across is also defining other formats which use the same extension or the same basic patterns within the format. I want the format I am researching to be identified correctly, but I also don’t want other formats to falsely identify as them either.
When using the DROID tool, if a file can’t be identified using a signature, the tool will then look to see if the extension matches any formats within the PRONOM registry, if it finds one, it will identify as that format with the identification method as “Extension”. This can be confusing and dangerous.
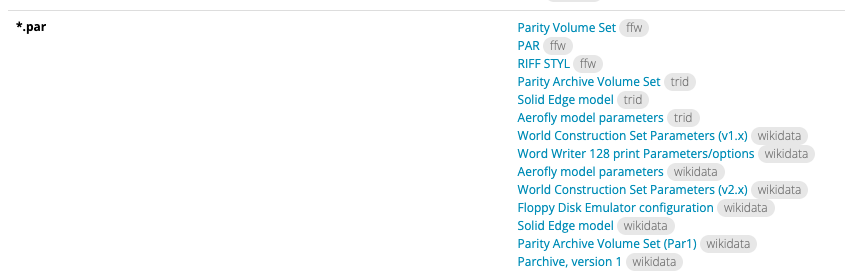
The topic of a format came up recently in reference to the extension PAR. Lets take a look at what we know about files with the extension PAR. Using the handy tool at digipres.org, we can see there are many formats using the PAR extension.
Apparently many people like to use the extension with their software. One might think their files with the PAR extension have to be in this list, and they would be wrong in that assumption. The PRONOM registry has no records of any format using the PAR extension. Hopefully we can add a few to help with proper identification instead of using the extension only.
A PArchive or Parity Volume Set is a group of file formats used in error correction and data integrity. Only the first version used the PAR extension, it is now obsolete with version 2 being the last stable version.
Pretty straightforward. The only thing that would have made it easier is if the first version used “PAR1”, but be glad they didn’t as that signature is used by another!
Apache Parquet is a more modern format used to store column-oriented data. At least they used a unique file extension!
Another common bit of software which uses the PAR extension is Solid Edge by Siemens. They use the PAR extension to encode their 3D parts format. For some reason this format still uses the OLE compound object container.
We will have to use the a container signature to correctly identify this format. There are also ASM and DFT formats which are also Solid Edge formats which use the same OLE container. Hopefully there are some unique features we can use to identify them.
One other file format which uses the PAR extension is not listed in any of the registries. Not in PRONOM, TrID, Wikidata, or others. I came across it while researching another format, DVD Studio Pro. On a Macintosh computer running the now discontinued DVD Studio Pro, one could save their DVD mastering project as a “file” which used the DSPPROJ extension. I use the term file loosely here as it wasn’t actually a file, it was a folder with an extension which MacOS would interpret as a single file. These are the package formats Apple used and still uses quite frequently. Moving this folder to another other system results in a folder of content.
About the Parse Files To use an asset in a project, DVD Studio Pro needs to know some general information about it, such as its length, type, and integrity. Video assets encoded within DVD Studio Pro can include this information in the encoded files, or can create separate files for it. Assets encoded by Compressor outside of DVD Studio Pro can include this information if you select the “Add DVD Studio Pro meta-data” option in the Extras pane of the Encoder settings. Assets encoded with other encoders, or with the “Add DVD Studio Pro meta-data” option disabled when using Compressor, must be parsed before DVD Studio Pro can use them. Parsing creates a small file, with the same name as the video asset and a “.par” extension that contains the required information. The parse file can take from several seconds to several minutes to create, depending on the size of the asset file.
This PAR format is called “Reflexw data-format“. This is a RAW format header that always is paired with a DAT file, together used to store geophysical wave data from devices such as GPR. Relexw is software made by Sandmeier geophysical research.
The PAR file samples I have don’t seem to have a consistent header as each have a unique set of bytes, but all of them have some similar bytes later in the file at around the 0x1D8 (472) offset:
It seems these sequence of bytes are the only consistent bytes among all my samples. I have no idea what they mean or reference. The specification does indicate some bytes which should lead to proper identification, but the integer used for the “HeaderMarker” is looking for a 4 byte “00 00 00 01”, which won’t be enough to cleanly identify the format. Love to hear what others can see from the spec. You can find some samples files here.
So we have some Parity files, Parts files, Parse files, Parquet files, and a Header file. I am sure other will be found and added to this lot. Hopefully the PAR files you run across will match one of these patterns! I am still working on a signature proposal. Stay Tuned!
A single file can often be self contained, having all that is needed to render itself with the correct software, but more and more often files need other files to function properly. Sometimes these groups of dependent files are within a container, such as a DOCX or ePub, but can also be found all sitting nicely in a folder. I say nicely, partly because the structure works, that is until they are treated as individual files and renamed or moved around breaking that interdependence on each other.
In the case of many Apple bundle files, they appear to be a single file when using on the MacOS, but as a folder on Windows or Linux. This can be very confusing. In other cases such as the DAISY Digital Talking Book format, it is simply a folder or disc with a few or many files within.
Current tools used to identify file formats, such as DROID, look at individual files, not groups of files to determine format. Each file within a folder may have a unique format, but when grouped with other specific formats they become something more. We will have to work on enhancing current tools if we want to avoid breaking these format types and losing their ability to render properly.
DAISY, or Digital Accessible Information System, is a type of Digital Book. The format was originally conceived in 1988 as a method to create a talking book, designed for the purpose of giving those who are visually impaired the ability to listen to books. It wasn’t until 1996, the DAISY Consortium was created in order to take the technology to those who needed it. The original version of the the DAISY format in 1994 was proprietary, but once they formed the consortium, they decided to adopt open standards for the format and in 1998, the DAISY 2.0 standard was released. You can read more on the Library of Congress Format Description page.
Lets take a look at a folder containing a DAISY 2.0 book.
We can see three different formats in this folder. The obvious well known MP3 files and an HTML file. We also see two files with the extension SMIL.
“Synchronized Multimedia Integration Language” or SMIL is a W3C XML standard used to describe multimedia presentations. It is used in the DAISY DTB as well as other applications, but we will focus on DAISY, and it is in its third version. A SMIL file has this structure:
A standard XML file with a link to a SMIL DTD and a root tag of <smil>. This format is recognized by PRONOM as fmt/205, although is often identified as a standard XML file. It seems the signature was created with a small offset which works with some SMIL files, but the gap between the end of the XML declaration and the start of the <smil> tag is only 20-86 bytes, not enough to allow for different character sets and full DTD URL’s. We will have to increase this gap in order to get all the SMIL files identified correctly.
With this update all the files in a DAISY 2.0 files should be identified individually, but as a set of files they make up the DAISY 2.0 format. This format requires the ncc.html file be present at the root of the folder or CD, so this file will aid in the manual identification of this format.
DAISY 3 was released in 2002 and standardized using the ANSI/NISO Z39.86 2002 name. It has been revised a couple times with the current revision being 2012. This update adds more functionality to the format with many new optional and required formats/files included in the folder. Here is a simple example:
The SMIL format is still included, along with MP3’s, but we have some addition formats. The NCX or “Navigation Control File”, the OPF or “Package file”, and the RES or “Resource file” are a few of them. The NCX file is the first file accessed as it lays out the navigation for the whole DTB. It is also XML:
This file is only recognized by DROID as a standard XML file. It probably should have unique identification like SMIL and with a root tag of <ncx>, that should be fairly easy to add.
The Package file with the extension OPF, is actually a format used by the openebook group, not to be confused by a format used by the Open Preservation Foundation 🤣. The Open Packaging Format is used and a DTB conforming to this standard must include exactly one Package File which must be a valid XML 1.0 document conforming to the OEBF Publication Structure 1.2 package.
The OPF format is also unknown to PRONOM and they identify as standard XML files as well. The root tag of “<package>” could be used elsewhere so the signature may need to reference the OEB package information.
The RES Resource file is also a standard XML and can be identified through its root tag of “<resources>” and resources DOCTYPE.
Now, adding these DAISY 3.0 formats will greatly increase the identification of this complex format. But we run into a problem with some of the software out there which generates these DAISY files, some of them include files not required by the format, but are included to be used by the different software. This can include some CSS files for formatting, additional XML, XSL files, DTD’s, and for DAISY files created by the PlexTalk software, additional project files.
The ncc.html file is here, indicating a DAISY 2.0 format, along with an MP3 and SMIL files, but including some additional formats.
In addition, when creating a project, four files with the extensions Ncc.imdn, ImdPhrInfo.imph, ImdTxtTabl.imtt, and METADATA.ini are automatically created. These files are called “Plextalk project files.” They store table of contents information, etc. (Plextalk project files generated by older versions of this product do not have METADATA.ini.)
I don’t have a METADATA.ini file to research, but I will be honest, these PlexTalk files will be hard to identify from their contents.
Looking at the IMPH file, there isn’t a lot of bytes which might indicate a format magic bytes. But I do see some patterns. The first 40 bytes all seem to be the same.
But making a signature from only 00 and FF might clash with other formats. It does appear that the 4 bytes FFFFFFFF occur every 40 bytes. This precision might be good enough if we repeat it a couple times.
The IMTT file is different. It appears to have information on the name, character set and all the files in the Daisy package. The first 4 bytes in my 14 samples either start with 17000000 or 18000000. Not knowing what the 17 or 18 refers to, I am hesitant to use it for identification. In between some of the data there is some consistent bytes, but at different offsets.
This format directly names the two other formats. Should be easy to look for the two file names in the header. The NCC html file in Daisy 2.0 and the NCX xml file in Daisy 3.0 are directory files so it makes sense this file would do the same.
Not sure if these signatures will hold up over time, but they are a start. It would be nice if all the files we are given to preserve would have convenient static magic bytes, but alas, many do not and we have to guess.
These Daisy formats illustrate a problem in preservation that doesn’t quite have a good solution. Each of these files are individually unique and can be identified, but as a whole they represent another unique format. Tying formats together to link their interdependence on each other will be no small task, but will be necessary not only to understanding the format, but to avoid separating the files, renaming, or rearranging breaking that interdependence.
I have added the update to SMIL and new signatures for the other formats to my GitHub repository. Feel free to test and change if you find additional samples or information.