In honor of #Marchintosh, I threatened in an earlier post to discuss The Writing Center, one of the many writing programs marketed by the Learning Company for the Mac. This one was developed by Datapak Software, Inc and I think they wanted to watch the world burn.

This format was different enough from the Student Writing Center and the “Ultimate Writing & Creativity Center” to need its own post. Moreover, I am pretty sure the developers of this software were actively trying to frustrate anyone trying to document the format. Let me explain.
In the early Macintosh world, very rarely were extensions used. Current systems use extensions to link the file to an application which can open the file. On the Mac, the system would use special attributes called Type / Creator codes. These codes were registered with Apple so they would be unique to a specific software and type of file. The codes used the FourCC system and unfortunately Apple never released a full list of codes used. Some folks over the years have tried to document as many as they can. Many used simple understandable codes, for example, A Microsoft Word document has a Type / Creator of W6BN / MSWD. The creator code of MSWD is very readable, and the type code W6BN is unique to a document from version 6 of Microsoft Word.

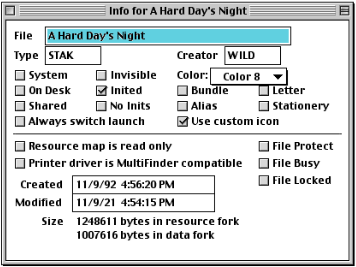
This Sample Report file from The Writing Center, when investigated with the ResEdit tool show interesting Type / Creator codes. If we look at the hexadecimals values for the codes. The first four bytes are the Type code and the second set of 4 bytes are the Creator code.
xattr -p com.apple.FinderInfo "Sample Report" 0000 0A 57 50 31 0A 1A 57 50 01 00 00 00 00 00 00 00 .WP1..WP........ getfileinfo "Sample Report" file: "Sample Report" type: "\nWP1" creator: "\n\^ZWP" attributes: avbstclInmedz created: 10/13/1990 00:10:54 modified: 07/25/1991 11:58:20
The first thing to know is the encoding for all Type / Creator codes is MacRoman, so if we look up the hexadecimal code for “0A” we learn it is the character for a new Line Feed, why in the world would you use the line feed character? The developers must have had a sense of humor, or are psychopaths, and I’m leaning toward the latter. Trying to put this character into any sort of spreadsheet or text based document with other codes throws everything off! When I try and use a spreadsheet with a group of codes and then use a script to look them up on the command line I get crazy formatting. Not to mentioned the second character in the creator code is “1A” which is a substitute character.
This is just one example of crazy characters being used in Type / Creator codes. Stay tuned for more on these in future discussions.
Even though the Type / Creator codes are very useful in identification of this format, often times the Finder attribute is lost. This can happen if the file is moved off an HFS disk, usually a network or through the internet. Then all we have is the binary data fork and a file with no extension. So finding a signature to identify this format is useful.
hexdump -C "Sample Report" | head 00000000 00 12 cf fc 00 00 05 78 00 00 00 00 01 18 01 eb |.......x........| 00000010 ff ff ff c4 ff ff ff c4 00 00 02 82 00 00 02 28 |...............(| 00000020 00 00 00 00 00 00 00 00 00 00 05 76 00 00 00 30 |...........v...0| 00000030 00 00 02 70 00 aa 00 00 05 76 00 00 00 30 00 00 |...p.....v...0..| 00000040 02 70 00 aa 00 00 00 00 00 00 00 00 00 00 00 00 |.p..............| 00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000060 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 12 |................| 00000070 d1 2c 00 00 05 3f 00 00 00 00 01 00 06 47 65 6e |.,...?.......Gen| 00000080 65 76 61 00 00 00 00 00 00 00 00 00 00 00 00 00 |eva.............| 00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0c |................| hexdump -C WC-s01 | head 00000000 03 df cd 9c 00 00 00 09 00 00 00 00 02 c3 02 64 |...............d| 00000010 00 00 00 00 00 00 00 00 00 00 00 59 00 00 02 64 |...........Y...d| 00000020 00 00 00 00 00 00 00 00 00 00 00 07 00 00 00 00 |................| 00000030 00 00 00 00 00 79 00 00 00 07 00 00 00 00 00 00 |.....y..........| 00000040 00 00 00 79 00 00 00 00 00 00 00 00 00 00 00 00 |...y............| 00000050 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 00000060 00 00 00 00 00 00 00 00 00 00 00 00 00 00 03 df |................| 00000070 cd 78 00 00 00 00 00 00 00 00 01 00 06 47 65 6e |.x...........Gen| 00000080 65 76 61 00 00 00 00 00 00 00 00 00 00 00 00 00 |eva.............| 00000090 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 0c |................|
Looking at the hexadecimal values of the header of a couple samples doesn’t initially look promising, the first few bytes are very different meaning there is no magic bytes at the beginning of the file. In fact the only thing the same is the mention of the Geneva font used in the document. Looking further into the files.
hexdump -C "Sample Report" 00000000 00 12 cf fc 00 00 05 78 00 00 00 00 01 18 01 eb |.......x........| ... 000000b0 00 00 00 00 00 00 00 02 84 28 ff ff 00 00 00 00 |.........(......| 000000c0 00 17 4e 26 00 12 d2 fc 00 00 00 00 00 12 d0 88 |..N&............| hexdump -C WC-s01 00000000 03 df cd 9c 00 00 00 09 00 00 00 00 02 c3 02 64 |...............d| ... 000000b0 00 00 00 00 00 00 00 02 84 28 ff ff 00 00 00 00 |.........(......| 000000c0 03 e3 a5 70 03 df cd 8c 00 00 00 00 03 df cd 64 |...p...........d| hexdump -C Stationery 00000000 00 12 d2 e8 00 00 00 02 00 00 00 00 01 17 01 ec |................| ... 000000b0 00 00 00 00 00 00 00 02 84 20 ff ff 00 00 00 00 |......... ......| 000000c0 00 17 56 f8 00 12 cd f8 00 00 00 00 00 12 ce 40 |..V............@|
The only bytes I could find near the beginning that seemed semi consistent is the highlighted bytes above. I did however notice some consistent bytes at the end of each of the files.
hexdump -C "Sample Report" | tail 00007250 e5 00 02 e5 00 02 e5 00 02 e5 00 02 e5 00 02 e5 |................| 00007260 00 02 e5 00 02 e5 00 02 e5 00 02 e5 00 ff 00 07 |................| 00007270 00 00 00 05 04 31 2e 30 30 00 09 00 00 00 05 04 |.....1.00.......| 00007280 31 2e 30 30 00 08 00 00 00 05 04 31 2e 30 30 00 |1.00.......1.00.| 00007290 0a 00 00 00 05 04 31 2e 30 30 00 0b 00 00 00 02 |......1.00......| 000072a0 00 00 00 0c 00 00 00 10 00 00 00 00 00 00 00 00 |................| 000072b0 00 00 00 01 00 00 00 01 00 11 00 00 00 08 00 2b |...............+| 000072c0 00 03 01 52 01 fd 00 13 00 00 00 02 00 00 7f ff |...R............| 000072d0 00 00 00 00 00 00 72 dc 7f ff ff ff |......r.....| hexdump -C WC-s01 | tail 000003c0 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| 000003d0 01 00 00 80 0c 00 08 00 05 00 00 00 00 01 d2 03 |................| 000003e0 ee dc 3e 00 00 00 00 00 07 00 00 00 01 00 00 09 |..>.............| 000003f0 00 00 00 01 00 00 08 00 00 00 01 00 00 0a 00 00 |................| 00000400 00 01 00 00 0b 00 00 00 02 00 00 00 0c 00 00 00 |................| 00000410 10 00 00 00 00 00 00 00 00 00 00 00 01 00 00 00 |................| 00000420 01 00 11 00 00 00 08 00 2b 00 c7 02 fd 03 3a 00 |........+.....:.| 00000430 13 00 00 00 02 00 00 7f ff 00 00 00 00 00 00 04 |................| 00000440 45 7f ff ff ff |E....| hexdump -C Stationery | tail 000039a0 00 02 e3 00 02 e3 00 02 e3 00 02 e3 00 02 e3 00 |................| 000039b0 02 e3 00 02 e3 00 02 e3 00 02 e3 00 02 e3 00 ff |................| 000039c0 00 07 00 00 00 05 04 31 2e 30 30 00 09 00 00 00 |.......1.00.....| 000039d0 05 04 31 2e 30 30 00 08 00 00 00 05 04 31 2e 30 |..1.00.......1.0| 000039e0 30 00 0a 00 00 00 05 04 31 2e 30 30 00 0b 00 00 |0.......1.00....| 000039f0 00 02 00 00 00 0c 00 00 00 10 00 00 00 00 00 00 |................| 00003a00 00 00 00 00 00 01 00 00 00 01 00 11 00 00 00 08 |................| 00003a10 00 2b 00 03 01 51 01 fe 00 13 00 00 00 02 00 00 |.+...Q..........| 00003a20 7f ff 00 00 00 00 00 00 3a 2e 7f ff ff ff |........:.....|
The four bytes at the end of each file by themselves would not be a good signature as there are many formats which end with a few “FF” sequences. But maybe combined with bytes near the beginning, a signature might be found. I added a couple samples to my Github page if you would like to take a look. In order to retain the extended attributes, I encoded the files as MacBinary.
lsar -L "Sample Report.bin" Sample Report.bin: MacBinary Sample Report: Name: Sample Report Size: 29.4 KB (29,404 bytes) Compressed size: 29.4 KB (29,440 bytes) Last modified: Thursday, July 25, 1991 at 12:58:20 PM Created: Saturday, October 13, 1990 at 1:10:54 AM Mac OS type code: ?WP1 (0x0a575031) Mac OS creator code: ??WP (0x0a1a5750) Mac OS Finder flags: 0x0100 Index in file: 0 Length of embedded data: 29404 Start of embedded data: 128 Original archive entry: Is an embedded MacBinary file: Yes