Let’s talk about Apple’s iWork software. Apple’s Office Suite of applications was first released in 2005 and provided a WordProcessor (Pages), Presentations (Keynote), and a little later, Spreadsheet (Numbers). They are exclusive to the Macintosh and iOS devices.
iWork was released in a few different versions. They get a little confusing as each application has its own version which all seemed to unify and stabilize in 2020. Here is a matrix of major versions.
| Version | Package or ZIP |
|---|---|
| iWork ’05 | Package |
| iWork ’06 | Package |
| iWork ’08 | Package |
| iWork ’09 | ZIP |
| iWork 2013 | Package |
| iWork 2014 | ZIP |
| iWork 2019 | ZIP |
| iWork 2020 | ZIP |
You may already be aware but MacOS can sometimes be weird. I use the term weird in a loving, sometimes proud way, but I admit, there was some “odd” choices made in regards to how applications and documents are used and stored files on a Mac.
On early Macintosh computers Apple used an interesting method of storing resources for applications and some file formats. The Resource Fork for an application contained all the “resources” needed to run in the operating system. It would contain all the icons, warning screens, graphics, sounds, etc. This held true until Mac OS X came along and then Apple started using a bundle or package format. Still in use today, what appears to be a single file or application is actually a folder of all the resources needed to run the application.
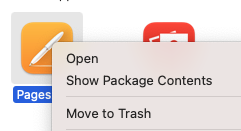
By right clicking or control clicking on the icon you can open the folder and see all the contents which make up the Application.
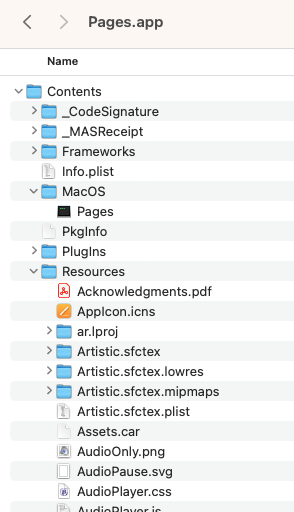
Nifty right? The MacOS which knows which extensions to treat as a package. If you were to move the application over to another system it would be a folder with the extension “.app”.
For an application I can see how this makes sense as it will only execute in the MacOS environment. The problem comes in when you use the same package method for the documents the application creates.

So instead of a single “file” with a bytestream, you get a folder of files which make up the file format. Here is Apple’s description:
Document Packages
If your document file formats are getting too complex to manage because of several disparate types of data, you might consider adopting a package format for your documents. Document packages give the illusion of a single document to users but provide you with flexibility in how you store the document data internally. Especially if you use several different types of standard data formats, such as JPEG, GIF, or XML, document packages make accessing and managing that data much easier.
Apple actually defines two similar methods:
Although bundles and packages are sometimes referred to interchangeably, they actually represent very distinct concepts:
- A package is any directory that the Finder presents to the user as if it were a single file.
- A bundle is a directory with a standardized hierarchical structure that holds executable code and the resources used by that code.
A couple years ago a processed digital collection made its way down to me. It had been processed by a new digital archivist and when I went to prepare the collection for preservation, I found a folder with the extension .pages and inside the folder a whole directory of files. Many of which they had renamed and arranged. Needless to say, I had to track down the original disk so I could properly preserve the file.
So looking back at the earlier table, iWork switched back and forth between the package format and a ZIP container. For preservation purposes, the ZIP container is easier to maintain outside the MacOS. Lets look a little closer at each. If you would like to follow along I have copied a few samples onto a hybrid ISO.
iWork ’05 through iWork ’08 used the same package format and structure. Because they are a package format, they are difficult to preserve as original files. I suppose you could zip them up, but probably the best option is to open with a current version of Pages and save to the newer ZIP container format.
tree iWork08/Keynote-06.key
├── Contents
│ └── PkgInfo
├── QuickLook
│ └── Thumbnail.jpg
├── index.apxl.gz
└── theme-files
├── Blue 2.jpg
├── Blue 2.tif
├── Cool Gray-2.jpg
├── Cool Gray.tif
├── Green-8.jpg
├── Green.tif
├── Headlines_bullet.pdf
├── Headlines_star.pdf
├── Orange 2.tif
├── Orange_2.jpg
├── Purple-6.jpg
├── Purple.tif
├── Red.jpg
├── Red.tif
├── endpoints.pdf
└── headlines_hi-res.jpg
iWork ’09 changed this practice. The documents saved from Pages, Keynote, and Numbers were contained in a ZIP file and can be identified using the PRONOM registry container signatures.
filename : 'iWork 2013/Pages2013-Sample09.pages'
filesize : 105900
modified : 2019-11-21T20:36:00-07:00
matches :
- ns : 'pronom'
id : 'fmt/1439'
format : 'Apple iWork Pages'
version : '09'
class : 'Word Processor'
basis : 'extension match pages; container name index.xml with byte match at 195, 76'
Sample09.pages Type = zip WARNINGS: Headers Error Physical Size = 105900 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:36:00 ..... 364773 22413 index.xml 2019-11-21 20:36:00 ..... 7007 7007 Hardcover_bullet_black.png 2019-11-21 20:36:00 ..... 69176 69176 Simple_Noise_2x.jpg 2019-11-21 20:36:00 ..... 232 232 buildVersionHistory.plist 2019-11-21 20:36:00 ..... 6406 6406 QuickLook/Thumbnail.png ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:36:00 447594 105234 5 files
Then Apple went back to a Package format with iWork 2013. For reasons unknown. But the content and structure changed. Its a package format with a Index.zip instead of index.xml
Pages2013-Sample.pages ├── Data │ └── Hardcover_bullet_black-13.png ├── Index.zip ├── Metadata │ ├── BuildVersionHistory.plist │ ├── DocumentIdentifier │ └── Properties.plist ├── preview-micro.jpg ├── preview-web.jpg └── preview.jpg 3 directories, 8 files
The ZIP within the package contains a new Apple format. IWA
Pages2013-Sample.pages/Index.zip Type = zip Physical Size = 39361 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:47:14 ..... 3860 3860 Index/Document.iwa 2019-11-21 20:47:14 ..... 26 26 Index/Tables/DataList.iwa 2019-11-21 20:47:14 ..... 336 336 Index/ViewState.iwa 2019-11-21 20:47:14 ..... 160 160 Index/CalculationEngine.iwa 2019-11-21 20:47:14 ..... 121 121 Index/DocumentStylesheet.iwa 2019-11-21 20:47:14 ..... 31931 31931 Index/ThemeStylesheet.iwa 2019-11-21 20:47:14 ..... 22 22 Index/AnnotationAuthorStorage.iwa 2019-11-21 20:47:14 ..... 1889 1889 Index/Metadata.iwa ------------------- ----- ------------ ------------ ------------------------ 2019-11-21 20:47:14 38345 38345 8 files
Luckily Apple came to their senses and went back to the ZIP container format for iWork 2014 and later. The container signature looks for the IWA file Apple started using with iWork 2013.
filename : 'iWork 2014/Pages2014-Sample.pages'
filesize : 66256
modified : 2019-11-22T00:03:56-07:00
errors :
matches :
- ns : 'pronom'
id : 'fmt/1441'
format : 'Apple iWork Document'
version : '14'
class : 'Presentation, Spreadsheet, Word Processor'
basis : 'extension match pages; container name Index/Document.iwa with byte match at 16, 6; name Metadata/Properties.plist with name only'
Path = iWork 2014/Pages2014-Sample.pages Type = zip Physical Size = 66256 Date Time Attr Size Compressed Name ------------------- ----- ------------ ------------ ------------------------ 2019-11-22 00:03:54 ..... 3930 3930 Index/Document.iwa 2019-11-22 00:03:54 ..... 364 364 Index/ViewState.iwa 2019-11-22 00:03:54 ..... 206 206 Index/CalculationEngine.iwa 2019-11-22 00:03:54 ..... 33573 33573 Index/DocumentStylesheet.iwa 2019-11-22 00:03:54 ..... 22 22 Index/AnnotationAuthorStorage.iwa 2019-11-22 00:03:54 ..... 23 23 Index/DocumentMetadata.iwa 2019-11-22 00:03:54 ..... 8761 8761 Index/Metadata.iwa 2019-11-22 00:03:54 ..... 322 322 Metadata/Properties.plist 2019-11-22 00:03:54 ..... 36 36 Metadata/DocumentIdentifier 2019-11-22 00:03:54 ..... 273 273 Metadata/BuildVersionHistory.plist 2019-11-22 00:03:54 ..... 14611 14611 preview.jpg 2019-11-22 00:03:54 ..... 838 838 preview-micro.jpg 2019-11-22 00:03:54 ..... 1571 1571 preview-web.jpg ------------------- ----- ------------ ------------ ------------------------ 2019-11-22 00:03:54 64530 64530 13 files
Now iWork was not the only Apple software to use the Package/Bundle format for their documents. Be advised the following software may save to the package format.
- Aperture Library
- Final Cut Pro X
- Soundtrack Pro
- Apple Motion
- Garageband Project
- DVD Studio Pro
- iMovie Project
- Logic Pro Project
- RTFd document
I remember a few years ago, Trent Reznor (NIN) decided to release a few of his tracks in the Garageband format. A little harder to find these days, but the good old wayback machine kept a copy for us! Grab them here. Be warned, they may be in the package format. Thanks Apple!