There really is no “Macintosh Format”, but there sure are a lot of formats you only find on the MacOS. From Resource Forks and iWork formats to unique sound formats, MacOS has them all! Majority of cross-platform software vendors have done a much better job in recent years in making their file formats the same across platforms, but for Apple, they love to make things unique, just for their platform.
Take EMLX for example. Seems to be a trend to add “X” to the end of an older format to breath new life into it. The EML format, or Electronic Mail, has existed for a few decades now, but in 2005 Apple updated their Apple Mail application to use a new format, EMLX.

As far as I know, Apple hasn’t released any documentation on the EMLX format, but many folks out there have asked the question and have been able to “reverse engineer” the format. Lets take a look.
An EMLX file consists of three parts:
- bytecount on first line;
- email content in MIME format (headers, body, attachments);
- Apple property list (plist) with metadata.
The bytecount is a variable number which consists of the total bytes starting from the start of the MIME format, including HTML, to the start of the XML property list. Lets look at a simple EMLX.
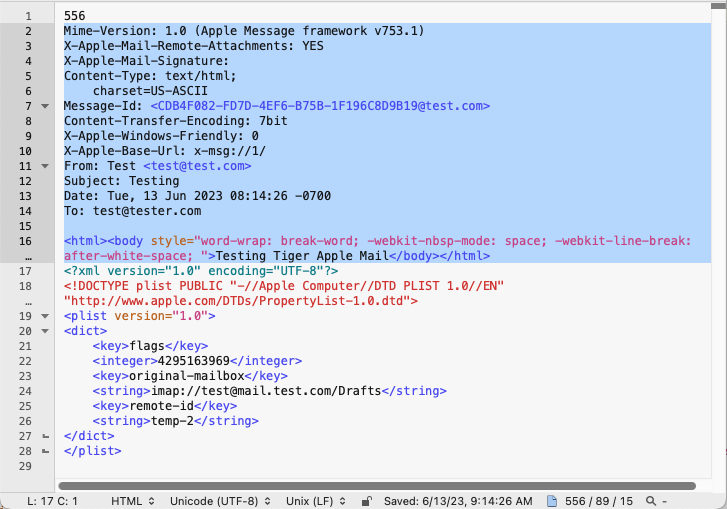
The byte count is on line 1 with the MIME email (EML) taking up the 556 bytes, then the XML plist at the end. You may ask, what is a plist? Well, it is another Apple (originally NextStep) invention which is embedded throughout the MacOS operating system. A Plist is usually an XML with keys but can also be in a binary format. The Plist can contain properties of the email within Apple Mail like special color flags, tagged as junk, date received and last reviewed.
If you do happen across an EMLX file or group of them, there are a few tools you can use to convert them to a plain old EML. There are python libraries or many other tools to do the job.
But first we need to be sure of identification beyond the extension. Adding this file format to PRONOM would help in identification for preservation purposes. If ran through PRONOM today we get:
filename : '9.emlx'
filesize : 18582
modified : 2023-10-26T22:16:25-06:00
errors :
matches :
- ns : 'pronom'
id : 'fmt/950'
format : 'MIME Email'
version : '1.0'
mime : 'message/rfc822'
class : 'Text (Structured)'
basis : 'byte match at [[31 17] [599 4] [339 6] [426 6] [90 14]]'
warning : 'extension mismatch'
Because the format has a EML plain text format within its structure, it is assumed to be an EML file. While technically accurate, Identifying as a unique EMLX format would be beneficial in a preservation system so you can properly assign risk and choose the right tool to parse or migrate.
In looking at the three parts of an EMLX format, we know the EML file is not a good way to show the difference as they are the same structure. The byte count on the first line is variable, so there is no static byte sequence to use for identification. That leaves the Plist section at the end to distinguish the difference.
The PRONOM entry for a Plist looks for the typical XML strings present in most XML files, but then uses the root element “<plist version=”1.0″>” for identification. We could combine the existing EML signature and the Plist signature to identify an EMLX, or just take the existing EML signature and put in a small byte sequence for the closing of the </plist> tag near the EOF? There would be a need for a priority over EML, both would essentially accomplish the same thing.
Take a look at latter idea on my GitHub page and tell me which makes the most sense.